mirror of
https://github.com/ccfos/nightingale.git
synced 2026-03-06 16:08:56 +00:00
Compare commits
148 Commits
docker_ima
...
refactor_h
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
7094665c25 | ||
|
|
f1a5c2065c | ||
|
|
6b9ceda9c1 | ||
|
|
7390d42e62 | ||
|
|
a35f879dc0 | ||
|
|
3fd4ea4853 | ||
|
|
20f0a9d16d | ||
|
|
5d4151983a | ||
|
|
83b5f12474 | ||
|
|
8c7bfb4f4a | ||
|
|
4ccf887920 | ||
|
|
546d9cb2cc | ||
|
|
391b42a399 | ||
|
|
a916a0fc6b | ||
|
|
da9f5fbb12 | ||
|
|
ad3cf58bf3 | ||
|
|
a77dc15e36 | ||
|
|
9ad51aeeff | ||
|
|
2c7f030ea5 | ||
|
|
039be7fc6c | ||
|
|
9bff2509a8 | ||
|
|
35b3cbb697 | ||
|
|
d81275b9c8 | ||
|
|
e29dd58823 | ||
|
|
b64aa03ccf | ||
|
|
3893cb00a5 | ||
|
|
4b6985c8af | ||
|
|
7cc9470823 | ||
|
|
b97dfce0ad | ||
|
|
357d3dff78 | ||
|
|
d0604f0c97 | ||
|
|
8fafa0075b | ||
|
|
caa23fbba1 | ||
|
|
4b9fea3cb2 | ||
|
|
f61a04f43f | ||
|
|
ef3588ff46 | ||
|
|
3e3210bb81 | ||
|
|
da7ef5a92e | ||
|
|
82b91164fe | ||
|
|
033d45309f | ||
|
|
60e9fb21f1 | ||
|
|
508006ad01 | ||
|
|
97d7b0574a | ||
|
|
c44aebd404 | ||
|
|
2afa921a5d | ||
|
|
313c820f1f | ||
|
|
02f0b4579b | ||
|
|
36eb308ef6 | ||
|
|
cd2db571cf | ||
|
|
a0cf12b171 | ||
|
|
8358ab4b81 | ||
|
|
0fc6cb8ef2 | ||
|
|
e1ab013c45 | ||
|
|
d984ad8bf4 | ||
|
|
86fe3c7c43 | ||
|
|
0f4478318e | ||
|
|
c0d0eb0e69 | ||
|
|
b62762b2e6 | ||
|
|
810ca0e469 | ||
|
|
33e3b224b9 | ||
|
|
24d7b2b1bf | ||
|
|
1d5ff1b28d | ||
|
|
ed5c8c5758 | ||
|
|
01f7860900 | ||
|
|
a6bb03c8ba | ||
|
|
e9150b2ae0 | ||
|
|
30d1ebd808 | ||
|
|
2f69d92055 | ||
|
|
deeb40b4a0 | ||
|
|
37f68fd52b | ||
|
|
73828e50b5 | ||
|
|
7e73850117 | ||
|
|
3a075e7681 | ||
|
|
4ec5612d78 | ||
|
|
817ed0ab1b | ||
|
|
63aa615761 | ||
|
|
2a36902760 | ||
|
|
bca9331182 | ||
|
|
199a23e385 | ||
|
|
c733f16cc7 | ||
|
|
81585649aa | ||
|
|
2c4422d657 | ||
|
|
aaf66cb386 | ||
|
|
cfed4d8318 | ||
|
|
606cd538ec | ||
|
|
bafb3b2546 | ||
|
|
9a0224697f | ||
|
|
23156552db | ||
|
|
36bca795fa | ||
|
|
b5503ae93e | ||
|
|
3c102e47ed | ||
|
|
60bf8139b1 | ||
|
|
fc0d077c9f | ||
|
|
3a610f7ea0 | ||
|
|
f8990ee85e | ||
|
|
88040bf277 | ||
|
|
1e15dc1f30 | ||
|
|
9880b466db | ||
|
|
b7780ebbdb | ||
|
|
1fa524b710 | ||
|
|
aa2c0cffce | ||
|
|
ed1c89fb7e | ||
|
|
988327dead | ||
|
|
5db168224e | ||
|
|
7622eba87f | ||
|
|
1cb58fedf7 | ||
|
|
7dcaec0a7b | ||
|
|
4f315cb6d5 | ||
|
|
9a2d898214 | ||
|
|
530561c038 | ||
|
|
fc68d2d598 | ||
|
|
1b40c38a7a | ||
|
|
d39d4cb91d | ||
|
|
e415538ffd | ||
|
|
05c767a803 | ||
|
|
923cff1c19 | ||
|
|
ef18d2a95f | ||
|
|
3abc4d0bfd | ||
|
|
a3ec69fe4a | ||
|
|
403466f872 | ||
|
|
81abd2f02a | ||
|
|
263c77cbbf | ||
|
|
ef42a78e59 | ||
|
|
4c7746b3b4 | ||
|
|
b142a5726e | ||
|
|
cc68b75489 | ||
|
|
1ce79e29d5 | ||
|
|
ee167ce0ba | ||
|
|
544cd02ef1 | ||
|
|
34ad6bc220 | ||
|
|
c7c694e70b | ||
|
|
dc26bb78d8 | ||
|
|
a0c635b830 | ||
|
|
0e95c29b7d | ||
|
|
cab9fed700 | ||
|
|
4ad47fb8f4 | ||
|
|
50345cb823 | ||
|
|
95bb67e66d | ||
|
|
90fbd9f16a | ||
|
|
5c8411eba1 | ||
|
|
03edb84d09 | ||
|
|
958a8c3ed1 | ||
|
|
a2a0b41909 | ||
|
|
64e1085766 | ||
|
|
5c97986908 | ||
|
|
66e291e3c3 | ||
|
|
365fcd5dd7 | ||
|
|
63690ba084 |
5
.gitignore
vendored
5
.gitignore
vendored
@@ -41,7 +41,8 @@ _test
|
||||
/docker/pub
|
||||
/docker/n9e
|
||||
/docker/mysqldata
|
||||
/etc.local
|
||||
/docker/experience_pg_vm/pgdata
|
||||
/etc.local*
|
||||
|
||||
.alerts
|
||||
.idea
|
||||
@@ -53,4 +54,4 @@ _test
|
||||
queries.active
|
||||
|
||||
/n9e-*
|
||||
|
||||
n9e.sql
|
||||
|
||||
@@ -2,6 +2,7 @@ before:
|
||||
hooks:
|
||||
# You may remove this if you don't use go modules.
|
||||
- go mod tidy
|
||||
- go install github.com/rakyll/statik
|
||||
|
||||
snapshot:
|
||||
name_template: '{{ .Tag }}'
|
||||
@@ -40,12 +41,40 @@ builds:
|
||||
ldflags:
|
||||
- -s -w
|
||||
- -X github.com/ccfos/nightingale/v6/pkg/version.Version={{ .Tag }}-{{.Commit}}
|
||||
- id: build-alert
|
||||
main: ./cmd/alert/
|
||||
binary: n9e-alert
|
||||
env:
|
||||
- CGO_ENABLED=0
|
||||
goos:
|
||||
- linux
|
||||
goarch:
|
||||
- amd64
|
||||
- arm64
|
||||
ldflags:
|
||||
- -s -w
|
||||
- -X github.com/ccfos/nightingale/v6/pkg/version.Version={{ .Tag }}-{{.Commit}}
|
||||
- id: build-pushgw
|
||||
main: ./cmd/pushgw/
|
||||
binary: n9e-pushgw
|
||||
env:
|
||||
- CGO_ENABLED=0
|
||||
goos:
|
||||
- linux
|
||||
goarch:
|
||||
- amd64
|
||||
- arm64
|
||||
ldflags:
|
||||
- -s -w
|
||||
- -X github.com/ccfos/nightingale/v6/pkg/version.Version={{ .Tag }}-{{.Commit}}
|
||||
|
||||
archives:
|
||||
- id: n9e
|
||||
builds:
|
||||
- build
|
||||
- build-cli
|
||||
- build-alert
|
||||
- build-pushgw
|
||||
format: tar.gz
|
||||
format_overrides:
|
||||
- goos: windows
|
||||
@@ -77,6 +106,7 @@ dockers:
|
||||
extra_files:
|
||||
- pub
|
||||
- etc
|
||||
- integrations
|
||||
use: buildx
|
||||
build_flag_templates:
|
||||
- "--platform=linux/amd64"
|
||||
@@ -86,10 +116,11 @@ dockers:
|
||||
goarch: arm64
|
||||
ids:
|
||||
- build
|
||||
dockerfile: docker/Dockerfile.goreleaser
|
||||
dockerfile: docker/Dockerfile.goreleaser.arm64
|
||||
extra_files:
|
||||
- pub
|
||||
- etc
|
||||
- integrations
|
||||
use: buildx
|
||||
build_flag_templates:
|
||||
- "--platform=linux/arm64/v8"
|
||||
|
||||
9
Makefile
9
Makefile
@@ -1,4 +1,4 @@
|
||||
.PHONY: start build
|
||||
.PHONY: prebuild start build
|
||||
|
||||
ROOT:=$(shell pwd -P)
|
||||
GIT_COMMIT:=$(shell git --work-tree ${ROOT} rev-parse 'HEAD^{commit}')
|
||||
@@ -6,6 +6,11 @@ _GIT_VERSION:=$(shell git --work-tree ${ROOT} describe --tags --abbrev=14 "${GIT
|
||||
TAG=$(shell echo "${_GIT_VERSION}" | awk -F"-" '{print $$1}')
|
||||
RELEASE_VERSION:="$(TAG)-$(GIT_COMMIT)"
|
||||
|
||||
prebuild:
|
||||
echo "begin download and embed the front-end file..."
|
||||
sh fe.sh
|
||||
echo "front-end file download and embedding completed."
|
||||
|
||||
all: build
|
||||
|
||||
build:
|
||||
@@ -17,7 +22,7 @@ build-alert:
|
||||
build-pushgw:
|
||||
go build -ldflags "-w -s -X github.com/ccfos/nightingale/v6/pkg/version.Version=$(RELEASE_VERSION)" -o n9e-pushgw ./cmd/pushgw/main.go
|
||||
|
||||
build-cli:
|
||||
build-cli:
|
||||
go build -ldflags "-w -s -X github.com/ccfos/nightingale/v6/pkg/version.Version=$(RELEASE_VERSION)" -o n9e-cli ./cmd/cli/main.go
|
||||
|
||||
run:
|
||||
|
||||
84
README.md
84
README.md
@@ -15,80 +15,41 @@
|
||||
<img alt="GitHub forks" src="https://img.shields.io/github/forks/ccfos/nightingale">
|
||||
<a href="https://github.com/ccfos/nightingale/graphs/contributors">
|
||||
<img alt="GitHub contributors" src="https://img.shields.io/github/contributors-anon/ccfos/nightingale"/></a>
|
||||
<a href="https://n9e-talk.slack.com/">
|
||||
<img alt="GitHub contributors" src="https://img.shields.io/badge/join%20slack-%23n9e-brightgreen.svg"/></a>
|
||||
<img alt="License" src="https://img.shields.io/badge/license-Apache--2.0-blue"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
An open-source cloud-native monitoring system that is <b>all-in-one</b> <br/>
|
||||
<b>Out-of-the-box</b>, it integrates data collection, visualization, and monitoring alert <br/>
|
||||
We recommend upgrading your <b>Prometheus + AlertManager + Grafana</b> combination to Nightingale!
|
||||
告警管理专家,一体化开源观测平台!
|
||||
</p>
|
||||
|
||||
[English](./README.md) | [中文](./README_ZH.md)
|
||||
[English](./README_en.md) | [中文](./README.md)
|
||||
|
||||
## 资料
|
||||
|
||||
## Highlighted Features
|
||||
- 文档:[https://flashcat.cloud/docs/](https://flashcat.cloud/docs/)
|
||||
- 论坛提问:[https://answer.flashcat.cloud/](https://answer.flashcat.cloud/)
|
||||
- 报Bug:[https://github.com/ccfos/nightingale/issues](https://github.com/ccfos/nightingale/issues/new?assignees=&labels=kind%2Fbug&projects=&template=bug_report.yml)
|
||||
- 商业版本:[企业版](https://mp.weixin.qq.com/s/FOwnnGPkRao2ZDV574EHrw) | [专业版](https://mp.weixin.qq.com/s/uM2a8QUDJEYwdBpjkbQDxA) 感兴趣请 [联系我们交流试用](https://flashcat.cloud/contact/)
|
||||
|
||||
- **Out-of-the-box**
|
||||
- Supports multiple deployment methods such as **Docker, Helm Chart, and cloud services**, integrates data collection, monitoring, and alerting into one system, and comes with various monitoring dashboards, quick views, and alert rule templates. **It greatly reduces the construction cost, learning cost, and usage cost of cloud-native monitoring systems**.
|
||||
- **Professional Alerting**
|
||||
- Provides visual alert configuration and management, supports various alert rules, offers the ability to configure silence and subscription rules, supports multiple alert delivery channels, and has features such as alert self-healing and event management.
|
||||
- **Cloud-Native**
|
||||
- Quickly builds an enterprise-level cloud-native monitoring system through a turnkey approach, supports multiple collectors such as [Categraf](https://github.com/flashcatcloud/categraf), Telegraf, and Grafana-agent, supports multiple data sources such as Prometheus, VictoriaMetrics, M3DB, ElasticSearch, and Jaeger, and is compatible with importing Grafana dashboards. **It seamlessly integrates with the cloud-native ecosystem**.
|
||||
- **High Performance and High Availability**
|
||||
- Due to the multi-data-source management engine of Nightingale and its excellent architecture design, and utilizing a high-performance time-series database, it can handle data collection, storage, and alert analysis scenarios with billions of time-series data, saving a lot of costs.
|
||||
- Nightingale components can be horizontally scaled with no single point of failure. It has been deployed in thousands of enterprises and tested in harsh production practices. Many leading Internet companies have used Nightingale for cluster machines with hundreds of nodes, processing billions of time-series data.
|
||||
- **Flexible Extension and Centralized Management**
|
||||
- Nightingale can be deployed on a 1-core 1G cloud host, deployed in a cluster of hundreds of machines, or run in Kubernetes. Time-series databases, alert engines, and other components can also be decentralized to various data centers and regions, balancing edge deployment with centralized management. **It solves the problem of data fragmentation and lack of unified views**.
|
||||
## 功能和特点
|
||||
|
||||
- **统一接入各种时序库**:支持对接 Prometheus、VictoriaMetrics、Thanos、Mimir、M3DB 等多种时序库,实现统一告警管理
|
||||
- **专业告警能力**:内置支持多种告警规则,可以扩展支持所有通知媒介,支持告警屏蔽、告警抑制、告警自愈、告警事件管理
|
||||
- **无缝搭配 [FlashDuty](https://flashcat.cloud/product/flashcat-duty/)**:实现告警聚合收敛、认领、升级、排班、IM集成,确保告警处理不遗漏,减少打扰,更好协同
|
||||
- **支持所有常见采集器**:支持 categraf、telegraf、grafana-agent、datadog-agent、给类 exporter 作为采集器,没有什么数据是不能监控的
|
||||
- **统一的观测平台**:从 v6 版本开始,支持接入 ElasticSearch、Jaeger 数据源,逐步实现日志、链路、指标的一体化观测
|
||||
|
||||
#### If you are using Prometheus and have one or more of the following requirement scenarios, it is recommended that you upgrade to Nightingale:
|
||||
|
||||
- Multiple systems such as Prometheus, Alertmanager, Grafana, etc. are fragmented and lack a unified view and cannot be used out of the box;
|
||||
- The way to manage Prometheus and Alertmanager by modifying configuration files has a big learning curve and is difficult to collaborate;
|
||||
- Too much data to scale-up your Prometheus cluster;
|
||||
- Multiple Prometheus clusters running in production environments, which faced high management and usage costs;
|
||||
|
||||
#### If you are using Zabbix and have the following scenarios, it is recommended that you upgrade to Nightingale:
|
||||
|
||||
- Monitoring too much data and wanting a better scalable solution;
|
||||
- A high learning curve and a desire for better efficiency of collaborative use in a multi-person, multi-team model;
|
||||
- Microservice and cloud-native architectures with variable monitoring data lifecycles and high monitoring data dimension bases, which are not easily adaptable to the Zabbix data model;
|
||||
|
||||
|
||||
#### If you are using [open-falcon](https://github.com/open-falcon/falcon-plus), we recommend you to upgrade to Nightingale:
|
||||
- For more information about open-falcon and Nightingale, please refer to read [Ten features and trends of cloud-native monitoring](https://mp.weixin.qq.com/s?__biz=MzkzNjI5OTM5Nw==&mid=2247483738&idx=1&sn=e8bdbb974a2cd003c1abcc2b5405dd18&chksm=c2a19fb0f5d616a63185cd79277a79a6b80118ef2185890d0683d2bb20451bd9303c78d083c5#rd)。
|
||||
|
||||
## Getting Started
|
||||
|
||||
[English Doc](https://n9e.github.io/) | [中文文档](http://n9e.flashcat.cloud/)
|
||||
|
||||
## Screenshots
|
||||
## 产品示意图
|
||||
|
||||
https://user-images.githubusercontent.com/792850/216888712-2565fcea-9df5-47bd-a49e-d60af9bd76e8.mp4
|
||||
|
||||
## Architecture
|
||||
|
||||
<img src="doc/img/arch-product.png" width="600">
|
||||
## 加入交流群
|
||||
|
||||
Nightingale monitoring can receive monitoring data reported by various collectors (such as [Categraf](https://github.com/flashcatcloud/categraf) , telegraf, grafana-agent, Prometheus, etc.) and write them to various popular time-series databases (such as Prometheus, M3DB, VictoriaMetrics, Thanos, TDEngine, etc.). It provides configuration capabilities for alert rules, silence rules, and subscription rules, as well as the ability to view monitoring data. It also provides automatic alarm self-healing mechanisms (such as automatically calling back to a webhook address or executing a script after an alarm is triggered), and the ability to store and manage historical alarm events and view them in groups.
|
||||
欢迎加入 QQ 交流群,群号:479290895,也可以扫下方二维码加入微信交流群:
|
||||
|
||||
If the performance of a standalone time-series database (such as Prometheus) has bottlenecks or poor disaster recovery, we recommend using [VictoriaMetrics](https://github.com/VictoriaMetrics/VictoriaMetrics). The VictoriaMetrics architecture is relatively simple, has excellent performance, and is easy to deploy and maintain. The architecture diagram is as shown above. For more detailed documentation on VictoriaMetrics, please refer to its [official website](https://victoriametrics.com/).
|
||||
|
||||
**We welcome you to participate in the Nightingale open-source project and community in various ways, including but not limited to**:
|
||||
- Adding and improving documentation => [n9e.github.io](https://n9e.github.io/)
|
||||
- Sharing your best practices and experience in using Nightingale monitoring => [Article sharing]((https://n9e.github.io/docs/prologue/share/))
|
||||
- Submitting product suggestions => [github issue](https://github.com/ccfos/nightingale/issues/new?assignees=&labels=kind%2Ffeature&template=enhancement.md)
|
||||
- Submitting code to make Nightingale monitoring faster, more stable, and easier to use => [github pull request](https://github.com/didi/nightingale/pulls)
|
||||
|
||||
|
||||
**Respecting, recognizing, and recording the work of every contributor** is the first guiding principle of the Nightingale open-source community. We advocate effective questioning, which not only respects the developer's time but also contributes to the accumulation of knowledge in the entire community
|
||||
- Before asking a question, please first refer to the [FAQ](https://www.gitlink.org.cn/ccfos/nightingale/wiki/faq)
|
||||
- We use [GitHub Discussions](https://github.com/ccfos/nightingale/discussions) as the communication forum. You can search and ask questions here.
|
||||
- We also recommend that you join ours [discard](https://discord.gg/qsRmtAuPw2) to exchange experiences with other Nightingale users.
|
||||
|
||||
|
||||
## Who is using Nightingale
|
||||
You can register your usage and share your experience by posting on **[Who is Using Nightingale](https://github.com/ccfos/nightingale/issues/897)**.
|
||||
<img src="doc/img/wecom.png" width="240">
|
||||
|
||||
## Stargazers over time
|
||||
[](https://starchart.cc/ccfos/nightingale)
|
||||
@@ -99,4 +60,9 @@ You can register your usage and share your experience by posting on **[Who is Us
|
||||
</a>
|
||||
|
||||
## License
|
||||
[Apache License V2.0](https://github.com/didi/nightingale/blob/main/LICENSE)
|
||||
[Apache License V2.0](https://github.com/didi/nightingale/blob/main/LICENSE)
|
||||
|
||||
## 社区管理
|
||||
|
||||
[夜莺开源项目和社区治理架构(草案)](./doc/community-governance.md)
|
||||
|
||||
|
||||
104
README_en.md
Normal file
104
README_en.md
Normal file
@@ -0,0 +1,104 @@
|
||||
<p align="center">
|
||||
<a href="https://github.com/ccfos/nightingale">
|
||||
<img src="doc/img/nightingale_logo_h.png" alt="nightingale - cloud native monitoring" width="240" /></a>
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<img alt="GitHub latest release" src="https://img.shields.io/github/v/release/ccfos/nightingale"/>
|
||||
<a href="https://n9e.github.io">
|
||||
<img alt="Docs" src="https://img.shields.io/badge/docs-get%20started-brightgreen"/></a>
|
||||
<a href="https://hub.docker.com/u/flashcatcloud">
|
||||
<img alt="Docker pulls" src="https://img.shields.io/docker/pulls/flashcatcloud/nightingale"/></a>
|
||||
<img alt="GitHub Repo stars" src="https://img.shields.io/github/stars/ccfos/nightingale">
|
||||
<img alt="GitHub Repo issues" src="https://img.shields.io/github/issues/ccfos/nightingale">
|
||||
<img alt="GitHub Repo issues closed" src="https://img.shields.io/github/issues-closed/ccfos/nightingale">
|
||||
<img alt="GitHub forks" src="https://img.shields.io/github/forks/ccfos/nightingale">
|
||||
<a href="https://github.com/ccfos/nightingale/graphs/contributors">
|
||||
<img alt="GitHub contributors" src="https://img.shields.io/github/contributors-anon/ccfos/nightingale"/></a>
|
||||
<a href="https://n9e-talk.slack.com/">
|
||||
<img alt="GitHub contributors" src="https://img.shields.io/badge/join%20slack-%23n9e-brightgreen.svg"/></a>
|
||||
<img alt="License" src="https://img.shields.io/badge/license-Apache--2.0-blue"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
An open-source cloud-native monitoring system that is <b>all-in-one</b> <br/>
|
||||
<b>Out-of-the-box</b>, it integrates data collection, visualization, and monitoring alert <br/>
|
||||
We recommend upgrading your <b>Prometheus + AlertManager + Grafana</b> combination to Nightingale!
|
||||
</p>
|
||||
|
||||
[English](./README.md) | [中文](./README_ZH.md)
|
||||
|
||||
|
||||
## Highlighted Features
|
||||
|
||||
- **Out-of-the-box**
|
||||
- Supports multiple deployment methods such as **Docker, Helm Chart, and cloud services**, integrates data collection, monitoring, and alerting into one system, and comes with various monitoring dashboards, quick views, and alert rule templates. **It greatly reduces the construction cost, learning cost, and usage cost of cloud-native monitoring systems**.
|
||||
- **Professional Alerting**
|
||||
- Provides visual alert configuration and management, supports various alert rules, offers the ability to configure silence and subscription rules, supports multiple alert delivery channels, and has features such as alert self-healing and event management.
|
||||
- **Cloud-Native**
|
||||
- Quickly builds an enterprise-level cloud-native monitoring system through a turnkey approach, supports multiple collectors such as [Categraf](https://github.com/flashcatcloud/categraf), Telegraf, and Grafana-agent, supports multiple data sources such as Prometheus, VictoriaMetrics, M3DB, ElasticSearch, and Jaeger, and is compatible with importing Grafana dashboards. **It seamlessly integrates with the cloud-native ecosystem**.
|
||||
- **High Performance and High Availability**
|
||||
- Due to the multi-data-source management engine of Nightingale and its excellent architecture design, and utilizing a high-performance time-series database, it can handle data collection, storage, and alert analysis scenarios with billions of time-series data, saving a lot of costs.
|
||||
- Nightingale components can be horizontally scaled with no single point of failure. It has been deployed in thousands of enterprises and tested in harsh production practices. Many leading Internet companies have used Nightingale for cluster machines with hundreds of nodes, processing billions of time-series data.
|
||||
- **Flexible Extension and Centralized Management**
|
||||
- Nightingale can be deployed on a 1-core 1G cloud host, deployed in a cluster of hundreds of machines, or run in Kubernetes. Time-series databases, alert engines, and other components can also be decentralized to various data centers and regions, balancing edge deployment with centralized management. **It solves the problem of data fragmentation and lack of unified views**.
|
||||
|
||||
|
||||
#### If you are using Prometheus and have one or more of the following requirement scenarios, it is recommended that you upgrade to Nightingale:
|
||||
|
||||
- Multiple systems such as Prometheus, Alertmanager, Grafana, etc. are fragmented and lack a unified view and cannot be used out of the box;
|
||||
- The way to manage Prometheus and Alertmanager by modifying configuration files has a big learning curve and is difficult to collaborate;
|
||||
- Too much data to scale-up your Prometheus cluster;
|
||||
- Multiple Prometheus clusters running in production environments, which faced high management and usage costs;
|
||||
|
||||
#### If you are using Zabbix and have the following scenarios, it is recommended that you upgrade to Nightingale:
|
||||
|
||||
- Monitoring too much data and wanting a better scalable solution;
|
||||
- A high learning curve and a desire for better efficiency of collaborative use in a multi-person, multi-team model;
|
||||
- Microservice and cloud-native architectures with variable monitoring data lifecycles and high monitoring data dimension bases, which are not easily adaptable to the Zabbix data model;
|
||||
|
||||
|
||||
#### If you are using [open-falcon](https://github.com/open-falcon/falcon-plus), we recommend you to upgrade to Nightingale:
|
||||
- For more information about open-falcon and Nightingale, please refer to read [Ten features and trends of cloud-native monitoring](https://mp.weixin.qq.com/s?__biz=MzkzNjI5OTM5Nw==&mid=2247483738&idx=1&sn=e8bdbb974a2cd003c1abcc2b5405dd18&chksm=c2a19fb0f5d616a63185cd79277a79a6b80118ef2185890d0683d2bb20451bd9303c78d083c5#rd)。
|
||||
|
||||
## Getting Started
|
||||
|
||||
[English Doc](https://n9e.github.io/) | [中文文档](http://n9e.flashcat.cloud/)
|
||||
|
||||
## Screenshots
|
||||
|
||||
https://user-images.githubusercontent.com/792850/216888712-2565fcea-9df5-47bd-a49e-d60af9bd76e8.mp4
|
||||
|
||||
## Architecture
|
||||
|
||||
<img src="doc/img/arch-product.png" width="600">
|
||||
|
||||
Nightingale monitoring can receive monitoring data reported by various collectors (such as [Categraf](https://github.com/flashcatcloud/categraf) , telegraf, grafana-agent, Prometheus, etc.) and write them to various popular time-series databases (such as Prometheus, M3DB, VictoriaMetrics, Thanos, TDEngine, etc.). It provides configuration capabilities for alert rules, silence rules, and subscription rules, as well as the ability to view monitoring data. It also provides automatic alarm self-healing mechanisms (such as automatically calling back to a webhook address or executing a script after an alarm is triggered), and the ability to store and manage historical alarm events and view them in groups.
|
||||
|
||||
If the performance of a standalone time-series database (such as Prometheus) has bottlenecks or poor disaster recovery, we recommend using [VictoriaMetrics](https://github.com/VictoriaMetrics/VictoriaMetrics). The VictoriaMetrics architecture is relatively simple, has excellent performance, and is easy to deploy and maintain. The architecture diagram is as shown above. For more detailed documentation on VictoriaMetrics, please refer to its [official website](https://victoriametrics.com/).
|
||||
|
||||
**We welcome you to participate in the Nightingale open-source project and community in various ways, including but not limited to**:
|
||||
- Adding and improving documentation => [n9e.github.io](https://n9e.github.io/)
|
||||
- Sharing your best practices and experience in using Nightingale monitoring => [Article sharing]((https://n9e.github.io/docs/prologue/share/))
|
||||
- Submitting product suggestions => [github issue](https://github.com/ccfos/nightingale/issues/new?assignees=&labels=kind%2Ffeature&template=enhancement.md)
|
||||
- Submitting code to make Nightingale monitoring faster, more stable, and easier to use => [github pull request](https://github.com/didi/nightingale/pulls)
|
||||
|
||||
|
||||
**Respecting, recognizing, and recording the work of every contributor** is the first guiding principle of the Nightingale open-source community. We advocate effective questioning, which not only respects the developer's time but also contributes to the accumulation of knowledge in the entire community
|
||||
- Before asking a question, please first refer to the [FAQ](https://www.gitlink.org.cn/ccfos/nightingale/wiki/faq)
|
||||
- We use [GitHub Discussions](https://github.com/ccfos/nightingale/discussions) as the communication forum. You can search and ask questions here.
|
||||
- We also recommend that you join ours [Slack channel](https://n9e-talk.slack.com/) to exchange experiences with other Nightingale users.
|
||||
|
||||
|
||||
## Who is using Nightingale
|
||||
You can register your usage and share your experience by posting on **[Who is Using Nightingale](https://github.com/ccfos/nightingale/issues/897)**.
|
||||
|
||||
## Stargazers over time
|
||||
[](https://starchart.cc/ccfos/nightingale)
|
||||
|
||||
## Contributors
|
||||
<a href="https://github.com/ccfos/nightingale/graphs/contributors">
|
||||
<img src="https://contrib.rocks/image?repo=ccfos/nightingale" />
|
||||
</a>
|
||||
|
||||
## License
|
||||
[Apache License V2.0](https://github.com/didi/nightingale/blob/main/LICENSE)
|
||||
@@ -23,10 +23,10 @@ type SMTPConfig struct {
|
||||
}
|
||||
|
||||
type HeartbeatConfig struct {
|
||||
IP string
|
||||
Interval int64
|
||||
Endpoint string
|
||||
ClusterName string
|
||||
IP string
|
||||
Interval int64
|
||||
Endpoint string
|
||||
EngineName string
|
||||
}
|
||||
|
||||
type Alerting struct {
|
||||
@@ -66,4 +66,8 @@ func (a *Alert) PreCheck() {
|
||||
if a.Heartbeat.Interval == 0 {
|
||||
a.Heartbeat.Interval = 1000
|
||||
}
|
||||
|
||||
if a.Heartbeat.EngineName == "" {
|
||||
a.Heartbeat.EngineName = "default"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -23,7 +23,6 @@ import (
|
||||
"github.com/ccfos/nightingale/v6/prom"
|
||||
"github.com/ccfos/nightingale/v6/pushgw/pconf"
|
||||
"github.com/ccfos/nightingale/v6/pushgw/writer"
|
||||
"github.com/ccfos/nightingale/v6/storage"
|
||||
)
|
||||
|
||||
func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
@@ -37,21 +36,12 @@ func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
db, err := storage.New(config.DB)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
ctx := ctx.NewContext(context.Background(), db)
|
||||
|
||||
redis, err := storage.NewRedis(config.Redis)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
ctx := ctx.NewContext(context.Background(), nil, false, config.CenterApi)
|
||||
|
||||
syncStats := memsto.NewSyncStats()
|
||||
alertStats := astats.NewSyncStats()
|
||||
|
||||
targetCache := memsto.NewTargetCache(ctx, syncStats, redis)
|
||||
targetCache := memsto.NewTargetCache(ctx, syncStats, nil)
|
||||
busiGroupCache := memsto.NewBusiGroupCache(ctx, syncStats)
|
||||
alertMuteCache := memsto.NewAlertMuteCache(ctx, syncStats)
|
||||
alertRuleCache := memsto.NewAlertRuleCache(ctx, syncStats)
|
||||
@@ -62,7 +52,7 @@ func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
|
||||
externalProcessors := process.NewExternalProcessors()
|
||||
|
||||
Start(config.Alert, config.Pushgw, syncStats, alertStats, externalProcessors, targetCache, busiGroupCache, alertMuteCache, alertRuleCache, notifyConfigCache, dsCache, ctx, promClients, false)
|
||||
Start(config.Alert, config.Pushgw, syncStats, alertStats, externalProcessors, targetCache, busiGroupCache, alertMuteCache, alertRuleCache, notifyConfigCache, dsCache, ctx, promClients)
|
||||
|
||||
r := httpx.GinEngine(config.Global.RunMode, config.HTTP)
|
||||
rt := router.New(config.HTTP, config.Alert, alertMuteCache, targetCache, busiGroupCache, alertStats, ctx, externalProcessors)
|
||||
@@ -77,7 +67,7 @@ func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
}
|
||||
|
||||
func Start(alertc aconf.Alert, pushgwc pconf.Pushgw, syncStats *memsto.Stats, alertStats *astats.Stats, externalProcessors *process.ExternalProcessorsType, targetCache *memsto.TargetCacheType, busiGroupCache *memsto.BusiGroupCacheType,
|
||||
alertMuteCache *memsto.AlertMuteCacheType, alertRuleCache *memsto.AlertRuleCacheType, notifyConfigCache *memsto.NotifyConfigCacheType, datasourceCache *memsto.DatasourceCacheType, ctx *ctx.Context, promClients *prom.PromClientMap, isCenter bool) {
|
||||
alertMuteCache *memsto.AlertMuteCacheType, alertRuleCache *memsto.AlertRuleCacheType, notifyConfigCache *memsto.NotifyConfigCacheType, datasourceCache *memsto.DatasourceCacheType, ctx *ctx.Context, promClients *prom.PromClientMap) {
|
||||
userCache := memsto.NewUserCache(ctx, syncStats)
|
||||
userGroupCache := memsto.NewUserGroupCache(ctx, syncStats)
|
||||
alertSubscribeCache := memsto.NewAlertSubscribeCache(ctx, syncStats)
|
||||
@@ -85,12 +75,12 @@ func Start(alertc aconf.Alert, pushgwc pconf.Pushgw, syncStats *memsto.Stats, al
|
||||
|
||||
go models.InitNotifyConfig(ctx, alertc.Alerting.TemplatesDir)
|
||||
|
||||
naming := naming.NewNaming(ctx, alertc.Heartbeat, isCenter)
|
||||
naming := naming.NewNaming(ctx, alertc.Heartbeat)
|
||||
|
||||
writers := writer.NewWriters(pushgwc)
|
||||
record.NewScheduler(alertc, recordingRuleCache, promClients, writers, alertStats)
|
||||
|
||||
eval.NewScheduler(isCenter, alertc, externalProcessors, alertRuleCache, targetCache, busiGroupCache, alertMuteCache, datasourceCache, promClients, naming, ctx, alertStats)
|
||||
eval.NewScheduler(alertc, externalProcessors, alertRuleCache, targetCache, busiGroupCache, alertMuteCache, datasourceCache, promClients, naming, ctx, alertStats)
|
||||
|
||||
dp := dispatch.NewDispatch(alertRuleCache, userCache, userGroupCache, alertSubscribeCache, targetCache, notifyConfigCache, alertc.Alerting, ctx)
|
||||
consumer := dispatch.NewConsumer(alertc.Alerting, ctx, dp)
|
||||
|
||||
@@ -8,6 +8,7 @@ import (
|
||||
"github.com/ccfos/nightingale/v6/alert/queue"
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
"github.com/ccfos/nightingale/v6/pkg/ctx"
|
||||
"github.com/ccfos/nightingale/v6/pkg/poster"
|
||||
|
||||
"github.com/toolkits/pkg/concurrent/semaphore"
|
||||
"github.com/toolkits/pkg/logger"
|
||||
@@ -82,78 +83,17 @@ func (e *Consumer) consumeOne(event *models.AlertCurEvent) {
|
||||
}
|
||||
|
||||
func (e *Consumer) persist(event *models.AlertCurEvent) {
|
||||
has, err := models.AlertCurEventExists(e.ctx, "hash=?", event.Hash)
|
||||
if err != nil {
|
||||
logger.Errorf("event_persist_check_exists_fail: %v rule_id=%d hash=%s", err, event.RuleId, event.Hash)
|
||||
return
|
||||
}
|
||||
|
||||
his := event.ToHis(e.ctx)
|
||||
|
||||
// 不管是告警还是恢复,全量告警里都要记录
|
||||
if err := his.Add(e.ctx); err != nil {
|
||||
logger.Errorf(
|
||||
"event_persist_his_fail: %v rule_id=%d cluster:%s hash=%s tags=%v timestamp=%d value=%s",
|
||||
err,
|
||||
event.RuleId,
|
||||
event.Cluster,
|
||||
event.Hash,
|
||||
event.TagsJSON,
|
||||
event.TriggerTime,
|
||||
event.TriggerValue,
|
||||
)
|
||||
}
|
||||
|
||||
if has {
|
||||
// 活跃告警表中有记录,删之
|
||||
err = models.AlertCurEventDelByHash(e.ctx, event.Hash)
|
||||
if !e.ctx.IsCenter {
|
||||
event.DB2FE()
|
||||
err := poster.PostByUrls(e.ctx, "/v1/n9e/event-persist", event)
|
||||
if err != nil {
|
||||
logger.Errorf("event_del_cur_fail: %v hash=%s", err, event.Hash)
|
||||
return
|
||||
logger.Errorf("event%+v persist err:%v", event, err)
|
||||
}
|
||||
|
||||
if !event.IsRecovered {
|
||||
// 恢复事件,从活跃告警列表彻底删掉,告警事件,要重新加进来新的event
|
||||
// use his id as cur id
|
||||
event.Id = his.Id
|
||||
if event.Id > 0 {
|
||||
if err := event.Add(e.ctx); err != nil {
|
||||
logger.Errorf(
|
||||
"event_persist_cur_fail: %v rule_id=%d cluster:%s hash=%s tags=%v timestamp=%d value=%s",
|
||||
err,
|
||||
event.RuleId,
|
||||
event.Cluster,
|
||||
event.Hash,
|
||||
event.TagsJSON,
|
||||
event.TriggerTime,
|
||||
event.TriggerValue,
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
if event.IsRecovered {
|
||||
// alert_cur_event表里没有数据,表示之前没告警,结果现在报了恢复,神奇....理论上不应该出现的
|
||||
return
|
||||
}
|
||||
|
||||
// use his id as cur id
|
||||
event.Id = his.Id
|
||||
if event.Id > 0 {
|
||||
if err := event.Add(e.ctx); err != nil {
|
||||
logger.Errorf(
|
||||
"event_persist_cur_fail: %v rule_id=%d cluster:%s hash=%s tags=%v timestamp=%d value=%s",
|
||||
err,
|
||||
event.RuleId,
|
||||
event.Cluster,
|
||||
event.Hash,
|
||||
event.TagsJSON,
|
||||
event.TriggerTime,
|
||||
event.TriggerValue,
|
||||
)
|
||||
}
|
||||
err := models.EventPersist(e.ctx, event)
|
||||
if err != nil {
|
||||
logger.Errorf("event%+v persist err:%v", event, err)
|
||||
}
|
||||
}
|
||||
|
||||
@@ -28,8 +28,9 @@ type Dispatch struct {
|
||||
|
||||
alerting aconf.Alerting
|
||||
|
||||
senders map[string]sender.Sender
|
||||
tpls map[string]*template.Template
|
||||
senders map[string]sender.Sender
|
||||
tpls map[string]*template.Template
|
||||
ExtraSenders map[string]sender.Sender
|
||||
|
||||
ctx *ctx.Context
|
||||
|
||||
@@ -50,8 +51,9 @@ func NewDispatch(alertRuleCache *memsto.AlertRuleCacheType, userCache *memsto.Us
|
||||
|
||||
alerting: alerting,
|
||||
|
||||
senders: make(map[string]sender.Sender),
|
||||
tpls: make(map[string]*template.Template),
|
||||
senders: make(map[string]sender.Sender),
|
||||
tpls: make(map[string]*template.Template),
|
||||
ExtraSenders: make(map[string]sender.Sender),
|
||||
|
||||
ctx: ctx,
|
||||
}
|
||||
@@ -89,6 +91,12 @@ func (e *Dispatch) relaodTpls() error {
|
||||
models.Telegram: sender.NewSender(models.Telegram, tmpTpls, smtp),
|
||||
}
|
||||
|
||||
e.RwLock.RLock()
|
||||
for channel, sender := range e.ExtraSenders {
|
||||
senders[channel] = sender
|
||||
}
|
||||
e.RwLock.RUnlock()
|
||||
|
||||
e.RwLock.Lock()
|
||||
e.tpls = tmpTpls
|
||||
e.senders = senders
|
||||
@@ -180,7 +188,7 @@ func (e *Dispatch) Send(rule *models.AlertRule, event *models.AlertCurEvent, not
|
||||
s := e.senders[channel]
|
||||
e.RwLock.RUnlock()
|
||||
if s == nil {
|
||||
logger.Warningf("no sender for channel: %s", channel)
|
||||
logger.Debugf("no sender for channel: %s", channel)
|
||||
continue
|
||||
}
|
||||
logger.Debugf("send event: %s, channel: %s", event.Hash, channel)
|
||||
@@ -191,7 +199,7 @@ func (e *Dispatch) Send(rule *models.AlertRule, event *models.AlertCurEvent, not
|
||||
}
|
||||
|
||||
// handle event callbacks
|
||||
sender.SendCallbacks(e.ctx, notifyTarget.ToCallbackList(), event, e.targetCache, e.notifyConfigCache.GetIbex())
|
||||
sender.SendCallbacks(e.ctx, notifyTarget.ToCallbackList(), event, e.targetCache, e.userCache, e.notifyConfigCache.GetIbex())
|
||||
|
||||
// handle global webhooks
|
||||
sender.SendWebhooks(notifyTarget.ToWebhookList(), event)
|
||||
|
||||
@@ -16,7 +16,6 @@ import (
|
||||
)
|
||||
|
||||
type Scheduler struct {
|
||||
isCenter bool
|
||||
// key: hash
|
||||
alertRules map[string]*AlertRuleWorker
|
||||
|
||||
@@ -38,11 +37,10 @@ type Scheduler struct {
|
||||
stats *astats.Stats
|
||||
}
|
||||
|
||||
func NewScheduler(isCenter bool, aconf aconf.Alert, externalProcessors *process.ExternalProcessorsType, arc *memsto.AlertRuleCacheType, targetCache *memsto.TargetCacheType,
|
||||
func NewScheduler(aconf aconf.Alert, externalProcessors *process.ExternalProcessorsType, arc *memsto.AlertRuleCacheType, targetCache *memsto.TargetCacheType,
|
||||
busiGroupCache *memsto.BusiGroupCacheType, alertMuteCache *memsto.AlertMuteCacheType, datasourceCache *memsto.DatasourceCacheType, promClients *prom.PromClientMap, naming *naming.Naming,
|
||||
ctx *ctx.Context, stats *astats.Stats) *Scheduler {
|
||||
scheduler := &Scheduler{
|
||||
isCenter: isCenter,
|
||||
aconf: aconf,
|
||||
alertRules: make(map[string]*AlertRuleWorker),
|
||||
|
||||
@@ -108,7 +106,7 @@ func (s *Scheduler) syncAlertRules() {
|
||||
alertRule := NewAlertRuleWorker(rule, dsId, processor, s.promClients, s.ctx)
|
||||
alertRuleWorkers[alertRule.Hash()] = alertRule
|
||||
}
|
||||
} else if rule.IsHostRule() && s.isCenter {
|
||||
} else if rule.IsHostRule() && s.ctx.IsCenter {
|
||||
// all host rule will be processed by center instance
|
||||
if !naming.DatasourceHashRing.IsHit(naming.HostDatasource, fmt.Sprintf("%d", rule.Id), s.aconf.Heartbeat.Endpoint) {
|
||||
continue
|
||||
|
||||
@@ -85,7 +85,7 @@ func (arw *AlertRuleWorker) Start() {
|
||||
func (arw *AlertRuleWorker) Eval() {
|
||||
cachedRule := arw.rule
|
||||
if cachedRule == nil {
|
||||
logger.Errorf("rule_eval:%s rule not found", arw.Key())
|
||||
//logger.Errorf("rule_eval:%s rule not found", arw.Key())
|
||||
return
|
||||
}
|
||||
|
||||
@@ -109,7 +109,7 @@ func (arw *AlertRuleWorker) Eval() {
|
||||
}
|
||||
|
||||
func (arw *AlertRuleWorker) Stop() {
|
||||
logger.Infof("%s stopped", arw.Key())
|
||||
logger.Infof("rule_eval %s stopped", arw.Key())
|
||||
close(arw.quit)
|
||||
}
|
||||
|
||||
@@ -202,7 +202,17 @@ func (arw *AlertRuleWorker) GetHostAnomalyPoint(ruleConfig string) []common.Anom
|
||||
}
|
||||
for _, target := range targets {
|
||||
m := make(map[string]string)
|
||||
target.FillTagsMap()
|
||||
for k, v := range target.TagsMap {
|
||||
m[k] = v
|
||||
}
|
||||
m["ident"] = target.Ident
|
||||
|
||||
bg := arw.processor.BusiGroupCache.GetByBusiGroupId(target.GroupId)
|
||||
if bg != nil && bg.LabelEnable == 1 {
|
||||
m["busigroup"] = bg.LabelValue
|
||||
}
|
||||
|
||||
lst = append(lst, common.NewAnomalyPoint(trigger.Type, m, now, float64(now-target.UpdateAt), trigger.Severity))
|
||||
}
|
||||
case "offset":
|
||||
@@ -211,10 +221,28 @@ func (arw *AlertRuleWorker) GetHostAnomalyPoint(ruleConfig string) []common.Anom
|
||||
logger.Errorf("rule_eval:%s query:%v, error:%v", arw.Key(), query, err)
|
||||
continue
|
||||
}
|
||||
var targetMap = make(map[string]*models.Target)
|
||||
for _, target := range targets {
|
||||
targetMap[target.Ident] = target
|
||||
}
|
||||
|
||||
hostOffsetMap := arw.processor.TargetCache.GetOffsetHost(targets, now, int64(trigger.Duration))
|
||||
for host, offset := range hostOffsetMap {
|
||||
m := make(map[string]string)
|
||||
target, exists := targetMap[host]
|
||||
if exists {
|
||||
target.FillTagsMap()
|
||||
for k, v := range target.TagsMap {
|
||||
m[k] = v
|
||||
}
|
||||
}
|
||||
m["ident"] = host
|
||||
|
||||
bg := arw.processor.BusiGroupCache.GetByBusiGroupId(target.GroupId)
|
||||
if bg != nil && bg.LabelEnable == 1 {
|
||||
m["busigroup"] = bg.LabelValue
|
||||
}
|
||||
|
||||
lst = append(lst, common.NewAnomalyPoint(trigger.Type, m, now, float64(offset), trigger.Severity))
|
||||
}
|
||||
case "pct_target_miss":
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
package naming
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"sync"
|
||||
|
||||
"github.com/toolkits/pkg/consistent"
|
||||
@@ -39,8 +40,8 @@ func RebuildConsistentHashRing(datasourceId int64, nodes []string) {
|
||||
}
|
||||
|
||||
func (chr *DatasourceHashRingType) GetNode(datasourceId int64, pk string) (string, error) {
|
||||
chr.RLock()
|
||||
defer chr.RUnlock()
|
||||
chr.Lock()
|
||||
defer chr.Unlock()
|
||||
_, exists := chr.Rings[datasourceId]
|
||||
if !exists {
|
||||
chr.Rings[datasourceId] = NewConsistentHashRing(int32(NodeReplicas), []string{})
|
||||
@@ -52,14 +53,18 @@ func (chr *DatasourceHashRingType) GetNode(datasourceId int64, pk string) (strin
|
||||
func (chr *DatasourceHashRingType) IsHit(datasourceId int64, pk string, currentNode string) bool {
|
||||
node, err := chr.GetNode(datasourceId, pk)
|
||||
if err != nil {
|
||||
logger.Debugf("datasource id:%d pk:%s failed to get node from hashring:%v", datasourceId, pk, err)
|
||||
if errors.Is(err, consistent.ErrEmptyCircle) {
|
||||
logger.Debugf("rule id:%s is not work, datasource id:%d is not assigned to active alert engine", pk, datasourceId)
|
||||
} else {
|
||||
logger.Debugf("rule id:%s is not work, datasource id:%d failed to get node from hashring:%v", pk, datasourceId, err)
|
||||
}
|
||||
return false
|
||||
}
|
||||
return node == currentNode
|
||||
}
|
||||
|
||||
func (chr *DatasourceHashRingType) Set(datasourceId int64, r *consistent.Consistent) {
|
||||
chr.RLock()
|
||||
defer chr.RUnlock()
|
||||
chr.Lock()
|
||||
defer chr.Unlock()
|
||||
chr.Rings[datasourceId] = r
|
||||
}
|
||||
|
||||
@@ -9,6 +9,7 @@ import (
|
||||
"github.com/ccfos/nightingale/v6/alert/aconf"
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
"github.com/ccfos/nightingale/v6/pkg/ctx"
|
||||
"github.com/ccfos/nightingale/v6/pkg/poster"
|
||||
|
||||
"github.com/toolkits/pkg/logger"
|
||||
)
|
||||
@@ -16,14 +17,12 @@ import (
|
||||
type Naming struct {
|
||||
ctx *ctx.Context
|
||||
heartbeatConfig aconf.HeartbeatConfig
|
||||
isCenter bool
|
||||
}
|
||||
|
||||
func NewNaming(ctx *ctx.Context, heartbeat aconf.HeartbeatConfig, isCenter bool) *Naming {
|
||||
func NewNaming(ctx *ctx.Context, heartbeat aconf.HeartbeatConfig) *Naming {
|
||||
naming := &Naming{
|
||||
ctx: ctx,
|
||||
heartbeatConfig: heartbeat,
|
||||
isCenter: isCenter,
|
||||
}
|
||||
naming.Heartbeats()
|
||||
return naming
|
||||
@@ -45,6 +44,10 @@ func (n *Naming) Heartbeats() error {
|
||||
}
|
||||
|
||||
func (n *Naming) loopDeleteInactiveInstances() {
|
||||
if !n.ctx.IsCenter {
|
||||
return
|
||||
}
|
||||
|
||||
interval := time.Duration(10) * time.Minute
|
||||
for {
|
||||
time.Sleep(interval)
|
||||
@@ -74,19 +77,19 @@ func (n *Naming) heartbeat() error {
|
||||
var err error
|
||||
|
||||
// 在页面上维护实例和集群的对应关系
|
||||
datasourceIds, err = models.GetDatasourceIdsByClusterName(n.ctx, n.heartbeatConfig.ClusterName)
|
||||
datasourceIds, err = models.GetDatasourceIdsByEngineName(n.ctx, n.heartbeatConfig.EngineName)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
if len(datasourceIds) == 0 {
|
||||
err := models.AlertingEngineHeartbeatWithCluster(n.ctx, n.heartbeatConfig.Endpoint, n.heartbeatConfig.ClusterName, 0)
|
||||
err := models.AlertingEngineHeartbeatWithCluster(n.ctx, n.heartbeatConfig.Endpoint, n.heartbeatConfig.EngineName, 0)
|
||||
if err != nil {
|
||||
logger.Warningf("heartbeat with cluster %s err:%v", "", err)
|
||||
}
|
||||
} else {
|
||||
for i := 0; i < len(datasourceIds); i++ {
|
||||
err := models.AlertingEngineHeartbeatWithCluster(n.ctx, n.heartbeatConfig.Endpoint, n.heartbeatConfig.ClusterName, datasourceIds[i])
|
||||
err := models.AlertingEngineHeartbeatWithCluster(n.ctx, n.heartbeatConfig.Endpoint, n.heartbeatConfig.EngineName, datasourceIds[i])
|
||||
if err != nil {
|
||||
logger.Warningf("heartbeat with cluster %d err:%v", datasourceIds[i], err)
|
||||
}
|
||||
@@ -112,10 +115,10 @@ func (n *Naming) heartbeat() error {
|
||||
localss[datasourceIds[i]] = newss
|
||||
}
|
||||
|
||||
if n.isCenter {
|
||||
if n.ctx.IsCenter {
|
||||
// 如果是中心节点,还需要处理 host 类型的告警规则,host 类型告警规则,和数据源无关,想复用下数据源的 hash ring,想用一个虚假的数据源 id 来处理
|
||||
// if is center node, we need to handle host type alerting rules, host type alerting rules are not related to datasource, we want to reuse the hash ring of datasource, we want to use a fake datasource id to handle it
|
||||
err := models.AlertingEngineHeartbeatWithCluster(n.ctx, n.heartbeatConfig.Endpoint, n.heartbeatConfig.ClusterName, HostDatasource)
|
||||
err := models.AlertingEngineHeartbeatWithCluster(n.ctx, n.heartbeatConfig.Endpoint, n.heartbeatConfig.EngineName, HostDatasource)
|
||||
if err != nil {
|
||||
logger.Warningf("heartbeat with cluster %s err:%v", "", err)
|
||||
}
|
||||
@@ -146,6 +149,11 @@ func (n *Naming) ActiveServers(datasourceId int64) ([]string, error) {
|
||||
return nil, fmt.Errorf("cluster is empty")
|
||||
}
|
||||
|
||||
if !n.ctx.IsCenter {
|
||||
lst, err := poster.GetByUrls[[]string](n.ctx, "/v1/n9e/servers-active?dsid="+fmt.Sprintf("%d", datasourceId))
|
||||
return lst, err
|
||||
}
|
||||
|
||||
// 30秒内有心跳,就认为是活的
|
||||
return models.AlertingEngineGetsInstances(n.ctx, "datasource_id = ? and clock > ?", datasourceId, time.Now().Unix()-30)
|
||||
}
|
||||
|
||||
@@ -59,7 +59,7 @@ type Processor struct {
|
||||
|
||||
atertRuleCache *memsto.AlertRuleCacheType
|
||||
TargetCache *memsto.TargetCacheType
|
||||
busiGroupCache *memsto.BusiGroupCacheType
|
||||
BusiGroupCache *memsto.BusiGroupCacheType
|
||||
alertMuteCache *memsto.AlertMuteCacheType
|
||||
datasourceCache *memsto.DatasourceCacheType
|
||||
|
||||
@@ -94,7 +94,7 @@ func NewProcessor(rule *models.AlertRule, datasourceId int64, atertRuleCache *me
|
||||
rule: rule,
|
||||
|
||||
TargetCache: targetCache,
|
||||
busiGroupCache: busiGroupCache,
|
||||
BusiGroupCache: busiGroupCache,
|
||||
alertMuteCache: alertMuteCache,
|
||||
atertRuleCache: atertRuleCache,
|
||||
datasourceCache: datasourceCache,
|
||||
@@ -113,13 +113,12 @@ func (p *Processor) Handle(anomalyPoints []common.AnomalyPoint, from string, inh
|
||||
// 这些信息的修改是不会引起worker restart的,但是确实会影响告警处理逻辑
|
||||
// 所以,这里直接从memsto.AlertRuleCache中获取并覆盖
|
||||
p.inhibit = inhibit
|
||||
p.rule = p.atertRuleCache.Get(p.rule.Id)
|
||||
cachedRule := p.rule
|
||||
cachedRule := p.atertRuleCache.Get(p.rule.Id)
|
||||
if cachedRule == nil {
|
||||
logger.Errorf("rule not found %+v", anomalyPoints)
|
||||
return
|
||||
}
|
||||
|
||||
p.rule = cachedRule
|
||||
now := time.Now().Unix()
|
||||
alertingKeys := map[string]struct{}{}
|
||||
|
||||
@@ -171,7 +170,7 @@ func (p *Processor) BuildEvent(anomalyPoint common.AnomalyPoint, from string, no
|
||||
event.Callbacks = p.rule.Callbacks
|
||||
event.CallbacksJSON = p.rule.CallbacksJSON
|
||||
event.Annotations = p.rule.Annotations
|
||||
event.AnnotationsJSON = p.rule.AnnotationsJSON
|
||||
event.AnnotationsJSON = make(map[string]string)
|
||||
event.RuleConfig = p.rule.RuleConfig
|
||||
event.RuleConfigJson = p.rule.RuleConfigJson
|
||||
event.Severity = anomalyPoint.Severity
|
||||
@@ -338,7 +337,7 @@ func (p *Processor) pushEventToQueue(e *models.AlertCurEvent) {
|
||||
func (p *Processor) RecoverAlertCurEventFromDb() {
|
||||
p.pendings = NewAlertCurEventMap(nil)
|
||||
|
||||
curEvents, err := models.AlertCurEventGetByRuleIdAndCluster(p.ctx, p.rule.Id, p.datasourceId)
|
||||
curEvents, err := models.AlertCurEventGetByRuleIdAndDsId(p.ctx, p.rule.Id, p.datasourceId)
|
||||
if err != nil {
|
||||
logger.Errorf("recover event from db for rule:%s failed, err:%s", p.Key(), err)
|
||||
p.fires = NewAlertCurEventMap(nil)
|
||||
@@ -378,18 +377,19 @@ func (p *Processor) fillTags(anomalyPoint common.AnomalyPoint) {
|
||||
t, err := template.New(fmt.Sprint(p.rule.Id)).Funcs(template.FuncMap(tplx.TemplateFuncMap)).Parse(text)
|
||||
if err != nil {
|
||||
tagValue = fmt.Sprintf("parse tag value failed, err:%s", err)
|
||||
tagsMap[arr[0]] = tagValue
|
||||
continue
|
||||
}
|
||||
|
||||
var body bytes.Buffer
|
||||
err = t.Execute(&body, e)
|
||||
if err != nil {
|
||||
tagValue = fmt.Sprintf("parse tag value failed, err:%s", err)
|
||||
tagsMap[arr[0]] = tagValue
|
||||
continue
|
||||
}
|
||||
|
||||
if err == nil {
|
||||
tagValue = body.String()
|
||||
}
|
||||
tagsMap[arr[0]] = tagValue
|
||||
tagsMap[arr[0]] = body.String()
|
||||
}
|
||||
|
||||
tagsMap["rulename"] = p.rule.Name
|
||||
@@ -411,7 +411,7 @@ func (p *Processor) mayHandleIdent() {
|
||||
|
||||
func (p *Processor) mayHandleGroup() {
|
||||
// handle bg
|
||||
bg := p.busiGroupCache.GetByBusiGroupId(p.rule.GroupId)
|
||||
bg := p.BusiGroupCache.GetByBusiGroupId(p.rule.GroupId)
|
||||
if bg != nil {
|
||||
p.groupName = bg.Name
|
||||
}
|
||||
|
||||
@@ -29,25 +29,26 @@ func New(httpConfig httpx.Config, alert aconf.Alert, amc *memsto.AlertMuteCacheT
|
||||
return &Router{
|
||||
HTTP: httpConfig,
|
||||
Alert: alert,
|
||||
AlertStats: astats,
|
||||
AlertMuteCache: amc,
|
||||
TargetCache: tc,
|
||||
BusiGroupCache: bgc,
|
||||
AlertStats: astats,
|
||||
Ctx: ctx,
|
||||
ExternalProcessors: externalProcessors,
|
||||
}
|
||||
}
|
||||
|
||||
func (rt *Router) Config(r *gin.Engine) {
|
||||
if !rt.HTTP.Alert.Enable {
|
||||
if !rt.HTTP.APIForService.Enable {
|
||||
return
|
||||
}
|
||||
|
||||
service := r.Group("/v1/n9e")
|
||||
if len(rt.HTTP.Alert.BasicAuth) > 0 {
|
||||
service.Use(gin.BasicAuth(rt.HTTP.Alert.BasicAuth))
|
||||
if len(rt.HTTP.APIForService.BasicAuth) > 0 {
|
||||
service.Use(gin.BasicAuth(rt.HTTP.APIForService.BasicAuth))
|
||||
}
|
||||
service.POST("/event", rt.pushEventToQueue)
|
||||
service.POST("/event-persist", rt.eventPersist)
|
||||
service.POST("/make-event", rt.makeEvent)
|
||||
}
|
||||
|
||||
|
||||
@@ -83,6 +83,13 @@ func (rt *Router) pushEventToQueue(c *gin.Context) {
|
||||
ginx.NewRender(c).Message(nil)
|
||||
}
|
||||
|
||||
func (rt *Router) eventPersist(c *gin.Context) {
|
||||
var event *models.AlertCurEvent
|
||||
ginx.BindJSON(c, &event)
|
||||
event.FE2DB()
|
||||
ginx.NewRender(c).Message(models.EventPersist(rt.Ctx, event))
|
||||
}
|
||||
|
||||
type eventForm struct {
|
||||
Alert bool `json:"alert"`
|
||||
AnomalyPoints []common.AnomalyPoint `json:"vectors"`
|
||||
|
||||
@@ -15,7 +15,7 @@ import (
|
||||
"github.com/toolkits/pkg/logger"
|
||||
)
|
||||
|
||||
func SendCallbacks(ctx *ctx.Context, urls []string, event *models.AlertCurEvent, targetCache *memsto.TargetCacheType, ibexConf aconf.Ibex) {
|
||||
func SendCallbacks(ctx *ctx.Context, urls []string, event *models.AlertCurEvent, targetCache *memsto.TargetCacheType, userCache *memsto.UserCacheType, ibexConf aconf.Ibex) {
|
||||
for _, url := range urls {
|
||||
if url == "" {
|
||||
continue
|
||||
@@ -23,7 +23,7 @@ func SendCallbacks(ctx *ctx.Context, urls []string, event *models.AlertCurEvent,
|
||||
|
||||
if strings.HasPrefix(url, "${ibex}") {
|
||||
if !event.IsRecovered {
|
||||
handleIbex(ctx, url, event, targetCache, ibexConf)
|
||||
handleIbex(ctx, url, event, targetCache, userCache, ibexConf)
|
||||
}
|
||||
continue
|
||||
}
|
||||
@@ -34,9 +34,9 @@ func SendCallbacks(ctx *ctx.Context, urls []string, event *models.AlertCurEvent,
|
||||
|
||||
resp, code, err := poster.PostJSON(url, 5*time.Second, event, 3)
|
||||
if err != nil {
|
||||
logger.Errorf("event_callback(rule_id=%d url=%s) fail, resp: %s, err: %v, code: %d", event.RuleId, url, string(resp), err, code)
|
||||
logger.Errorf("event_callback_fail(rule_id=%d url=%s), resp: %s, err: %v, code: %d", event.RuleId, url, string(resp), err, code)
|
||||
} else {
|
||||
logger.Infof("event_callback(rule_id=%d url=%s) succ, resp: %s, code: %d", event.RuleId, url, string(resp), code)
|
||||
logger.Infof("event_callback_succ(rule_id=%d url=%s), resp: %s, code: %d", event.RuleId, url, string(resp), code)
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -60,7 +60,7 @@ type TaskCreateReply struct {
|
||||
Dat int64 `json:"dat"` // task.id
|
||||
}
|
||||
|
||||
func handleIbex(ctx *ctx.Context, url string, event *models.AlertCurEvent, targetCache *memsto.TargetCacheType, ibexConf aconf.Ibex) {
|
||||
func handleIbex(ctx *ctx.Context, url string, event *models.AlertCurEvent, targetCache *memsto.TargetCacheType, userCache *memsto.UserCacheType, ibexConf aconf.Ibex) {
|
||||
arr := strings.Split(url, "/")
|
||||
|
||||
var idstr string
|
||||
@@ -103,7 +103,7 @@ func handleIbex(ctx *ctx.Context, url string, event *models.AlertCurEvent, targe
|
||||
|
||||
// check perm
|
||||
// tpl.GroupId - host - account 三元组校验权限
|
||||
can, err := canDoIbex(ctx, tpl.UpdateBy, tpl, host, targetCache)
|
||||
can, err := canDoIbex(ctx, tpl.UpdateBy, tpl, host, targetCache, userCache)
|
||||
if err != nil {
|
||||
logger.Errorf("event_callback_ibex: check perm fail: %v", err)
|
||||
return
|
||||
@@ -154,6 +154,7 @@ func handleIbex(ctx *ctx.Context, url string, event *models.AlertCurEvent, targe
|
||||
// write db
|
||||
record := models.TaskRecord{
|
||||
Id: res.Dat,
|
||||
EventId: event.Id,
|
||||
GroupId: tpl.GroupId,
|
||||
IbexAddress: ibexConf.Address,
|
||||
IbexAuthUser: ibexConf.BasicAuthUser,
|
||||
@@ -175,12 +176,8 @@ func handleIbex(ctx *ctx.Context, url string, event *models.AlertCurEvent, targe
|
||||
}
|
||||
}
|
||||
|
||||
func canDoIbex(ctx *ctx.Context, username string, tpl *models.TaskTpl, host string, targetCache *memsto.TargetCacheType) (bool, error) {
|
||||
user, err := models.UserGetByUsername(ctx, username)
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
|
||||
func canDoIbex(ctx *ctx.Context, username string, tpl *models.TaskTpl, host string, targetCache *memsto.TargetCacheType, userCache *memsto.UserCacheType) (bool, error) {
|
||||
user := userCache.GetByUsername(username)
|
||||
if user != nil && user.IsAdmin() {
|
||||
return true, nil
|
||||
}
|
||||
|
||||
@@ -49,7 +49,7 @@ func (ds *DingtalkSender) Send(ctx MessageContext) {
|
||||
body = dingtalk{
|
||||
Msgtype: "markdown",
|
||||
Markdown: dingtalkMarkdown{
|
||||
Title: ctx.Rule.Name,
|
||||
Title: ctx.Event.RuleName,
|
||||
Text: message,
|
||||
},
|
||||
}
|
||||
@@ -57,8 +57,8 @@ func (ds *DingtalkSender) Send(ctx MessageContext) {
|
||||
body = dingtalk{
|
||||
Msgtype: "markdown",
|
||||
Markdown: dingtalkMarkdown{
|
||||
Title: ctx.Rule.Name,
|
||||
Text: message + " " + strings.Join(ats, " "),
|
||||
Title: ctx.Event.RuleName,
|
||||
Text: message + "\n" + strings.Join(ats, " "),
|
||||
},
|
||||
At: dingtalkAt{
|
||||
AtMobiles: ats,
|
||||
|
||||
@@ -31,7 +31,7 @@ func (es *EmailSender) Send(ctx MessageContext) {
|
||||
if es.subjectTpl != nil {
|
||||
subject = BuildTplMessage(es.subjectTpl, ctx.Event)
|
||||
} else {
|
||||
subject = ctx.Rule.Name
|
||||
subject = ctx.Event.RuleName
|
||||
}
|
||||
content := BuildTplMessage(es.contentTpl, ctx.Event)
|
||||
es.WriteEmail(subject, content, tos)
|
||||
|
||||
@@ -59,6 +59,7 @@ func SendMM(message MatterMostMessage) {
|
||||
u, err := url.Parse(message.Tokens[i])
|
||||
if err != nil {
|
||||
logger.Errorf("mm_sender: failed to parse error=%v", err)
|
||||
continue
|
||||
}
|
||||
|
||||
v, err := url.ParseQuery(u.RawQuery)
|
||||
|
||||
@@ -35,7 +35,7 @@ func alertingCallScript(stdinBytes []byte, notifyScript models.NotifyScript) {
|
||||
if file.IsExist(fpath) {
|
||||
oldContent, err := file.ToString(fpath)
|
||||
if err != nil {
|
||||
logger.Errorf("event_notify: read script file err: %v", err)
|
||||
logger.Errorf("event_script_notify_fail: read script file err: %v", err)
|
||||
return
|
||||
}
|
||||
|
||||
@@ -47,13 +47,13 @@ func alertingCallScript(stdinBytes []byte, notifyScript models.NotifyScript) {
|
||||
if rewrite {
|
||||
_, err := file.WriteString(fpath, config.Content)
|
||||
if err != nil {
|
||||
logger.Errorf("event_notify: write script file err: %v", err)
|
||||
logger.Errorf("event_script_notify_fail: write script file err: %v", err)
|
||||
return
|
||||
}
|
||||
|
||||
err = os.Chmod(fpath, 0777)
|
||||
if err != nil {
|
||||
logger.Errorf("event_notify: chmod script file err: %v", err)
|
||||
logger.Errorf("event_script_notify_fail: chmod script file err: %v", err)
|
||||
return
|
||||
}
|
||||
}
|
||||
@@ -70,7 +70,7 @@ func alertingCallScript(stdinBytes []byte, notifyScript models.NotifyScript) {
|
||||
|
||||
err := startCmd(cmd)
|
||||
if err != nil {
|
||||
logger.Errorf("event_notify: run cmd err: %v", err)
|
||||
logger.Errorf("event_script_notify_fail: run cmd err: %v", err)
|
||||
return
|
||||
}
|
||||
|
||||
@@ -78,20 +78,20 @@ func alertingCallScript(stdinBytes []byte, notifyScript models.NotifyScript) {
|
||||
|
||||
if isTimeout {
|
||||
if err == nil {
|
||||
logger.Errorf("event_notify: timeout and killed process %s", fpath)
|
||||
logger.Errorf("event_script_notify_fail: timeout and killed process %s", fpath)
|
||||
}
|
||||
|
||||
if err != nil {
|
||||
logger.Errorf("event_notify: kill process %s occur error %v", fpath, err)
|
||||
logger.Errorf("event_script_notify_fail: kill process %s occur error %v", fpath, err)
|
||||
}
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
if err != nil {
|
||||
logger.Errorf("event_notify: exec script %s occur error: %v, output: %s", fpath, err, buf.String())
|
||||
logger.Errorf("event_script_notify_fail: exec script %s occur error: %v, output: %s", fpath, err, buf.String())
|
||||
return
|
||||
}
|
||||
|
||||
logger.Infof("event_notify: exec %s output: %s", fpath, buf.String())
|
||||
logger.Infof("event_script_notify_ok: exec %s output: %s", fpath, buf.String())
|
||||
}
|
||||
|
||||
@@ -54,6 +54,7 @@ func BuildTplMessage(tpl *template.Template, event *models.AlertCurEvent) string
|
||||
if tpl == nil {
|
||||
return "tpl for current sender not found, please check configuration"
|
||||
}
|
||||
|
||||
var body bytes.Buffer
|
||||
if err := tpl.Execute(&body, event); err != nil {
|
||||
return err.Error()
|
||||
|
||||
@@ -53,7 +53,7 @@ func SendWebhooks(webhooks []*models.Webhook, event *models.AlertCurEvent) {
|
||||
var resp *http.Response
|
||||
resp, err = client.Do(req)
|
||||
if err != nil {
|
||||
logger.Warningf("WebhookCallError, ruleId: [%d], eventId: [%d], url: [%s], error: [%s]", event.RuleId, event.Id, conf.Url, err)
|
||||
logger.Errorf("event_webhook_fail, ruleId: [%d], eventId: [%d], url: [%s], error: [%s]", event.RuleId, event.Id, conf.Url, err)
|
||||
continue
|
||||
}
|
||||
|
||||
@@ -63,6 +63,6 @@ func SendWebhooks(webhooks []*models.Webhook, event *models.AlertCurEvent) {
|
||||
body, _ = ioutil.ReadAll(resp.Body)
|
||||
}
|
||||
|
||||
logger.Debugf("alertingWebhook done, url: %s, response code: %d, body: %s", conf.Url, resp.StatusCode, string(body))
|
||||
logger.Debugf("event_webhook_succ, url: %s, response code: %d, body: %s", conf.Url, resp.StatusCode, string(body))
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,18 +1,12 @@
|
||||
package cconf
|
||||
|
||||
import (
|
||||
"github.com/gin-gonic/gin"
|
||||
)
|
||||
|
||||
type Center struct {
|
||||
Plugins []Plugin
|
||||
BasicAuth gin.Accounts
|
||||
MetricsYamlFile string
|
||||
OpsYamlFile string
|
||||
BuiltinIntegrationsDir string
|
||||
I18NHeaderKey string
|
||||
MetricDesc MetricDescType
|
||||
TargetMetrics map[string]string
|
||||
AnonymousAccess AnonymousAccess
|
||||
}
|
||||
|
||||
|
||||
@@ -4,7 +4,6 @@ import (
|
||||
"path"
|
||||
|
||||
"github.com/toolkits/pkg/file"
|
||||
"github.com/toolkits/pkg/runner"
|
||||
)
|
||||
|
||||
// metricDesc , As load map happens before read map, there is no necessary to use concurrent map for metric desc store
|
||||
@@ -33,10 +32,10 @@ func GetMetricDesc(lang, metric string) string {
|
||||
return MetricDesc.CommonDesc[metric]
|
||||
}
|
||||
|
||||
func LoadMetricsYaml(metricsYamlFile string) error {
|
||||
func LoadMetricsYaml(configDir, metricsYamlFile string) error {
|
||||
fp := metricsYamlFile
|
||||
if fp == "" {
|
||||
fp = path.Join(runner.Cwd, "etc", "metrics.yaml")
|
||||
fp = path.Join(configDir, "metrics.yaml")
|
||||
}
|
||||
if !file.IsExist(fp) {
|
||||
return nil
|
||||
|
||||
@@ -4,7 +4,6 @@ import (
|
||||
"path"
|
||||
|
||||
"github.com/toolkits/pkg/file"
|
||||
"github.com/toolkits/pkg/runner"
|
||||
)
|
||||
|
||||
var Operations = Operation{}
|
||||
@@ -19,10 +18,10 @@ type Ops struct {
|
||||
Ops []string `yaml:"ops" json:"ops"`
|
||||
}
|
||||
|
||||
func LoadOpsYaml(opsYamlFile string) error {
|
||||
func LoadOpsYaml(configDir string, opsYamlFile string) error {
|
||||
fp := opsYamlFile
|
||||
if fp == "" {
|
||||
fp = path.Join(runner.Cwd, "etc", "ops.yaml")
|
||||
fp = path.Join(configDir, "ops.yaml")
|
||||
}
|
||||
if !file.IsExist(fp) {
|
||||
return nil
|
||||
|
||||
@@ -33,8 +33,8 @@ func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
return nil, fmt.Errorf("failed to init config: %v", err)
|
||||
}
|
||||
|
||||
cconf.LoadMetricsYaml(config.Center.MetricsYamlFile)
|
||||
cconf.LoadOpsYaml(config.Center.OpsYamlFile)
|
||||
cconf.LoadMetricsYaml(configDir, config.Center.MetricsYamlFile)
|
||||
cconf.LoadOpsYaml(configDir, config.Center.OpsYamlFile)
|
||||
|
||||
logxClean, err := logx.Init(config.Log)
|
||||
if err != nil {
|
||||
@@ -47,7 +47,7 @@ func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
ctx := ctx.NewContext(context.Background(), db)
|
||||
ctx := ctx.NewContext(context.Background(), db, true)
|
||||
models.InitRoot(ctx)
|
||||
|
||||
redis, err := storage.NewRedis(config.Redis)
|
||||
@@ -56,7 +56,7 @@ func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
}
|
||||
|
||||
metas := metas.New(redis)
|
||||
idents := idents.New(db)
|
||||
idents := idents.New(ctx)
|
||||
|
||||
syncStats := memsto.NewSyncStats()
|
||||
alertStats := astats.NewSyncStats()
|
||||
@@ -73,12 +73,12 @@ func Initialize(configDir string, cryptoKey string) (func(), error) {
|
||||
promClients := prom.NewPromClient(ctx, config.Alert.Heartbeat)
|
||||
|
||||
externalProcessors := process.NewExternalProcessors()
|
||||
alert.Start(config.Alert, config.Pushgw, syncStats, alertStats, externalProcessors, targetCache, busiGroupCache, alertMuteCache, alertRuleCache, notifyConfigCache, dsCache, ctx, promClients, true)
|
||||
alert.Start(config.Alert, config.Pushgw, syncStats, alertStats, externalProcessors, targetCache, busiGroupCache, alertMuteCache, alertRuleCache, notifyConfigCache, dsCache, ctx, promClients)
|
||||
|
||||
writers := writer.NewWriters(config.Pushgw)
|
||||
|
||||
alertrtRouter := alertrt.New(config.HTTP, config.Alert, alertMuteCache, targetCache, busiGroupCache, alertStats, ctx, externalProcessors)
|
||||
centerRouter := centerrt.New(config.HTTP, config.Center, cconf.Operations, dsCache, notifyConfigCache, promClients, redis, sso, ctx, metas)
|
||||
centerRouter := centerrt.New(config.HTTP, config.Center, cconf.Operations, dsCache, notifyConfigCache, promClients, redis, sso, ctx, metas, targetCache)
|
||||
pushgwRouter := pushgwrt.New(config.HTTP, config.Pushgw, targetCache, busiGroupCache, idents, writers, ctx)
|
||||
|
||||
r := httpx.GinEngine(config.Global.RunMode, config.HTTP)
|
||||
|
||||
@@ -95,11 +95,10 @@ func (s *Set) updateTargets(m map[string]models.HostMeta) error {
|
||||
return nil
|
||||
}
|
||||
|
||||
var values []interface{}
|
||||
newMap := make(map[string]interface{}, count)
|
||||
for ident, meta := range m {
|
||||
values = append(values, models.WrapIdent(ident))
|
||||
values = append(values, meta)
|
||||
newMap[models.WrapIdent(ident)] = meta
|
||||
}
|
||||
err := s.redis.MSet(context.Background(), values...).Err()
|
||||
err := storage.MSet(context.Background(), s.redis, newMap)
|
||||
return err
|
||||
}
|
||||
|
||||
@@ -3,7 +3,6 @@ package router
|
||||
import (
|
||||
"fmt"
|
||||
"net/http"
|
||||
"path"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
@@ -11,15 +10,17 @@ import (
|
||||
"github.com/ccfos/nightingale/v6/center/cstats"
|
||||
"github.com/ccfos/nightingale/v6/center/metas"
|
||||
"github.com/ccfos/nightingale/v6/center/sso"
|
||||
_ "github.com/ccfos/nightingale/v6/front/statik"
|
||||
"github.com/ccfos/nightingale/v6/memsto"
|
||||
"github.com/ccfos/nightingale/v6/pkg/aop"
|
||||
"github.com/ccfos/nightingale/v6/pkg/ctx"
|
||||
"github.com/ccfos/nightingale/v6/pkg/httpx"
|
||||
"github.com/ccfos/nightingale/v6/prom"
|
||||
"github.com/ccfos/nightingale/v6/storage"
|
||||
"github.com/toolkits/pkg/ginx"
|
||||
|
||||
"github.com/gin-gonic/gin"
|
||||
"github.com/rakyll/statik/fs"
|
||||
"github.com/toolkits/pkg/logger"
|
||||
)
|
||||
|
||||
type Router struct {
|
||||
@@ -31,12 +32,13 @@ type Router struct {
|
||||
PromClients *prom.PromClientMap
|
||||
Redis storage.Redis
|
||||
MetaSet *metas.Set
|
||||
TargetCache *memsto.TargetCacheType
|
||||
Sso *sso.SsoClient
|
||||
Ctx *ctx.Context
|
||||
}
|
||||
|
||||
func New(httpConfig httpx.Config, center cconf.Center, operations cconf.Operation, ds *memsto.DatasourceCacheType, ncc *memsto.NotifyConfigCacheType,
|
||||
pc *prom.PromClientMap, redis storage.Redis, sso *sso.SsoClient, ctx *ctx.Context, metaSet *metas.Set) *Router {
|
||||
pc *prom.PromClientMap, redis storage.Redis, sso *sso.SsoClient, ctx *ctx.Context, metaSet *metas.Set, tc *memsto.TargetCacheType) *Router {
|
||||
return &Router{
|
||||
HTTP: httpConfig,
|
||||
Center: center,
|
||||
@@ -45,9 +47,10 @@ func New(httpConfig httpx.Config, center cconf.Center, operations cconf.Operatio
|
||||
NotifyConfigCache: ncc,
|
||||
PromClients: pc,
|
||||
Redis: redis,
|
||||
MetaSet: metaSet,
|
||||
TargetCache: tc,
|
||||
Sso: sso,
|
||||
Ctx: ctx,
|
||||
MetaSet: metaSet,
|
||||
}
|
||||
}
|
||||
|
||||
@@ -86,24 +89,32 @@ func languageDetector(i18NHeaderKey string) gin.HandlerFunc {
|
||||
}
|
||||
}
|
||||
|
||||
func (rt *Router) configNoRoute(r *gin.Engine) {
|
||||
func (rt *Router) configNoRoute(r *gin.Engine, fs *http.FileSystem) {
|
||||
r.NoRoute(func(c *gin.Context) {
|
||||
arr := strings.Split(c.Request.URL.Path, ".")
|
||||
suffix := arr[len(arr)-1]
|
||||
|
||||
switch suffix {
|
||||
case "png", "jpeg", "jpg", "svg", "ico", "gif", "css", "js", "html", "htm", "gz", "zip", "map":
|
||||
c.File(path.Join(strings.Split("pub/"+c.Request.URL.Path, "/")...))
|
||||
c.FileFromFS(c.Request.URL.Path, *fs)
|
||||
default:
|
||||
c.File(path.Join("pub", "index.html"))
|
||||
c.FileFromFS("/", *fs)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
func (rt *Router) Config(r *gin.Engine) {
|
||||
|
||||
r.Use(stat())
|
||||
r.Use(languageDetector(rt.Center.I18NHeaderKey))
|
||||
r.Use(aop.Recovery())
|
||||
|
||||
statikFS, err := fs.New()
|
||||
if err != nil {
|
||||
logger.Errorf("cannot create statik fs: %v", err)
|
||||
}
|
||||
r.StaticFS("/pub", statikFS)
|
||||
|
||||
pagesPrefix := "/api/n9e"
|
||||
pages := r.Group(pagesPrefix)
|
||||
{
|
||||
@@ -112,10 +123,12 @@ func (rt *Router) Config(r *gin.Engine) {
|
||||
pages.Any("/proxy/:id/*url", rt.dsProxy)
|
||||
pages.POST("/query-range-batch", rt.promBatchQueryRange)
|
||||
pages.POST("/query-instant-batch", rt.promBatchQueryInstant)
|
||||
pages.GET("/datasource/brief", rt.datasourceBriefs)
|
||||
} else {
|
||||
pages.Any("/proxy/:id/*url", rt.auth(), rt.dsProxy)
|
||||
pages.POST("/query-range-batch", rt.auth(), rt.promBatchQueryRange)
|
||||
pages.POST("/query-instant-batch", rt.auth(), rt.promBatchQueryInstant)
|
||||
pages.GET("/datasource/brief", rt.auth(), rt.datasourceBriefs)
|
||||
}
|
||||
|
||||
pages.POST("/auth/login", rt.jwtMock(), rt.loginPost)
|
||||
@@ -129,6 +142,7 @@ func (rt *Router) Config(r *gin.Engine) {
|
||||
pages.GET("/auth/callback", rt.loginCallback)
|
||||
pages.GET("/auth/callback/cas", rt.loginCallbackCas)
|
||||
pages.GET("/auth/callback/oauth", rt.loginCallbackOAuth)
|
||||
pages.GET("/auth/perms", rt.allPerms)
|
||||
|
||||
pages.GET("/metrics/desc", rt.metricsDescGetFile)
|
||||
pages.POST("/metrics/desc", rt.metricsDescGetMap)
|
||||
@@ -188,11 +202,7 @@ func (rt *Router) Config(r *gin.Engine) {
|
||||
pages.GET("/dashboards/builtin/list", rt.builtinBoardGets)
|
||||
pages.GET("/builtin-boards-cates", rt.auth(), rt.user(), rt.builtinBoardCateGets)
|
||||
pages.POST("/builtin-boards-detail", rt.auth(), rt.user(), rt.builtinBoardDetailGets)
|
||||
pages.GET("/integrations/icon/:cate/:name", func(c *gin.Context) {
|
||||
cate := ginx.UrlParamStr(c, "cate")
|
||||
fp := "integrations/" + cate + "/icon/" + ginx.UrlParamStr(c, "name")
|
||||
c.File(path.Join(fp))
|
||||
})
|
||||
pages.GET("/integrations/icon/:cate/:name", rt.builtinIcon)
|
||||
|
||||
pages.GET("/busi-group/:id/boards", rt.auth(), rt.user(), rt.perm("/dashboards"), rt.bgro(), rt.boardGets)
|
||||
pages.POST("/busi-group/:id/boards", rt.auth(), rt.user(), rt.perm("/dashboards/add"), rt.bgrw(), rt.boardAdd)
|
||||
@@ -288,7 +298,7 @@ func (rt *Router) Config(r *gin.Engine) {
|
||||
|
||||
pages.GET("/role/:id/ops", rt.auth(), rt.admin(), rt.operationOfRole)
|
||||
pages.PUT("/role/:id/ops", rt.auth(), rt.admin(), rt.roleBindOperation)
|
||||
pages.GET("operation", rt.operations)
|
||||
pages.GET("/operation", rt.operations)
|
||||
|
||||
pages.GET("/notify-tpls", rt.auth(), rt.admin(), rt.notifyTplGets)
|
||||
pages.PUT("/notify-tpl/content", rt.auth(), rt.admin(), rt.notifyTplUpdateContent)
|
||||
@@ -314,17 +324,20 @@ func (rt *Router) Config(r *gin.Engine) {
|
||||
pages.PUT("/notify-config", rt.auth(), rt.admin(), rt.notifyConfigPut)
|
||||
}
|
||||
|
||||
if rt.HTTP.Service.Enable {
|
||||
if rt.HTTP.APIForService.Enable {
|
||||
service := r.Group("/v1/n9e")
|
||||
if len(rt.HTTP.Service.BasicAuth) > 0 {
|
||||
service.Use(gin.BasicAuth(rt.HTTP.Service.BasicAuth))
|
||||
if len(rt.HTTP.APIForService.BasicAuth) > 0 {
|
||||
service.Use(gin.BasicAuth(rt.HTTP.APIForService.BasicAuth))
|
||||
}
|
||||
{
|
||||
service.Any("/prometheus/*url", rt.dsProxy)
|
||||
service.POST("/users", rt.userAddPost)
|
||||
service.GET("/users", rt.userFindAll)
|
||||
|
||||
service.GET("/targets", rt.targetGets)
|
||||
service.GET("/user-groups", rt.userGroupGetsByService)
|
||||
service.GET("/user-group-members", rt.userGroupMemberGetsByService)
|
||||
|
||||
service.GET("/targets", rt.targetGetsByService)
|
||||
service.GET("/targets/tags", rt.targetGetTags)
|
||||
service.POST("/targets/tags", rt.targetBindTagsByService)
|
||||
service.DELETE("/targets/tags", rt.targetUnbindTagsByService)
|
||||
@@ -336,36 +349,56 @@ func (rt *Router) Config(r *gin.Engine) {
|
||||
service.GET("/alert-rule/:arid", rt.alertRuleGet)
|
||||
service.GET("/alert-rules", rt.alertRulesGetByService)
|
||||
|
||||
service.GET("/alert-subscribes", rt.alertSubscribeGetsByService)
|
||||
|
||||
service.GET("/busi-groups", rt.busiGroupGetsByService)
|
||||
|
||||
service.GET("/datasources", rt.datasourceGetsByService)
|
||||
service.GET("/datasource-ids", rt.getDatasourceIds)
|
||||
service.POST("/server-heartbeat", rt.serverHeartbeat)
|
||||
service.GET("/servers-active", rt.serversActive)
|
||||
|
||||
service.GET("/recording-rules", rt.recordingRuleGetsByService)
|
||||
|
||||
service.GET("/alert-mutes", rt.alertMuteGets)
|
||||
service.POST("/alert-mutes", rt.alertMuteAddByService)
|
||||
service.DELETE("/alert-mutes", rt.alertMuteDel)
|
||||
|
||||
service.GET("/alert-cur-events", rt.alertCurEventsList)
|
||||
service.GET("/alert-cur-events-get-by-rid", rt.alertCurEventsGetByRid)
|
||||
service.GET("/alert-his-events", rt.alertHisEventsList)
|
||||
service.GET("/alert-his-event/:eid", rt.alertHisEventGet)
|
||||
|
||||
service.GET("/config/:id", rt.configGet)
|
||||
service.GET("/configs", rt.configsGet)
|
||||
service.GET("/config", rt.configGetByKey)
|
||||
service.PUT("/configs", rt.configsPut)
|
||||
service.POST("/configs", rt.configsPost)
|
||||
service.DELETE("/configs", rt.configsDel)
|
||||
|
||||
service.POST("/conf-prop/encrypt", rt.confPropEncrypt)
|
||||
service.POST("/conf-prop/decrypt", rt.confPropDecrypt)
|
||||
|
||||
service.GET("/statistic", rt.statistic)
|
||||
|
||||
service.GET("/notify-tpls", rt.notifyTplGets)
|
||||
|
||||
service.POST("/task-record-add", rt.taskRecordAdd)
|
||||
}
|
||||
}
|
||||
|
||||
if rt.HTTP.Heartbeat.Enable {
|
||||
if rt.HTTP.APIForAgent.Enable {
|
||||
heartbeat := r.Group("/v1/n9e")
|
||||
{
|
||||
if len(rt.HTTP.Heartbeat.BasicAuth) > 0 {
|
||||
heartbeat.Use(gin.BasicAuth(rt.HTTP.Heartbeat.BasicAuth))
|
||||
if len(rt.HTTP.APIForAgent.BasicAuth) > 0 {
|
||||
heartbeat.Use(gin.BasicAuth(rt.HTTP.APIForAgent.BasicAuth))
|
||||
}
|
||||
heartbeat.POST("/heartbeat", rt.heartbeat)
|
||||
}
|
||||
}
|
||||
|
||||
rt.configNoRoute(r)
|
||||
rt.configNoRoute(r, &statikFS)
|
||||
|
||||
}
|
||||
|
||||
func Render(c *gin.Context, data, msg interface{}) {
|
||||
@@ -387,9 +420,9 @@ func Dangerous(c *gin.Context, v interface{}, code ...int) {
|
||||
switch t := v.(type) {
|
||||
case string:
|
||||
if t != "" {
|
||||
c.JSON(http.StatusOK, gin.H{"error": gin.H{"message": v}})
|
||||
c.JSON(http.StatusOK, gin.H{"error": v})
|
||||
}
|
||||
case error:
|
||||
c.JSON(http.StatusOK, gin.H{"error": gin.H{"message": t.Error()}})
|
||||
c.JSON(http.StatusOK, gin.H{"error": t.Error()})
|
||||
}
|
||||
}
|
||||
|
||||
@@ -128,6 +128,13 @@ func (rt *Router) alertCurEventsCardDetails(c *gin.Context) {
|
||||
ginx.NewRender(c).Data(list, err)
|
||||
}
|
||||
|
||||
// alertCurEventsGetByRid
|
||||
func (rt *Router) alertCurEventsGetByRid(c *gin.Context) {
|
||||
rid := ginx.QueryInt64(c, "rid")
|
||||
dsId := ginx.QueryInt64(c, "dsid")
|
||||
ginx.NewRender(c).Data(models.AlertCurEventGetByRuleIdAndDsId(rt.Ctx, rid, dsId))
|
||||
}
|
||||
|
||||
// 列表方式,拉取活跃告警
|
||||
func (rt *Router) alertCurEventsList(c *gin.Context) {
|
||||
stime, etime := getTimeRange(c)
|
||||
|
||||
@@ -27,7 +27,12 @@ func (rt *Router) alertRuleGets(c *gin.Context) {
|
||||
}
|
||||
|
||||
func (rt *Router) alertRulesGetByService(c *gin.Context) {
|
||||
prods := strings.Split(ginx.QueryStr(c, "prods", ""), ",")
|
||||
prods := []string{}
|
||||
prodStr := ginx.QueryStr(c, "prods", "")
|
||||
if prodStr != "" {
|
||||
prods = strings.Split(ginx.QueryStr(c, "prods", ""), ",")
|
||||
}
|
||||
|
||||
query := ginx.QueryStr(c, "query", "")
|
||||
algorithm := ginx.QueryStr(c, "algorithm", "")
|
||||
cluster := ginx.QueryStr(c, "cluster", "")
|
||||
|
||||
@@ -110,3 +110,8 @@ func (rt *Router) alertSubscribeDel(c *gin.Context) {
|
||||
|
||||
ginx.NewRender(c).Message(models.AlertSubscribeDel(rt.Ctx, f.Ids))
|
||||
}
|
||||
|
||||
func (rt *Router) alertSubscribeGetsByService(c *gin.Context) {
|
||||
lst, err := models.AlertSubscribeGetsByService(rt.Ctx)
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
@@ -298,3 +298,14 @@ func (rt *Router) builtinBoardGet(c *gin.Context) {
|
||||
|
||||
ginx.Bomb(http.StatusBadRequest, "%s not found", name)
|
||||
}
|
||||
|
||||
func (rt *Router) builtinIcon(c *gin.Context) {
|
||||
fp := rt.Center.BuiltinIntegrationsDir
|
||||
if fp == "" {
|
||||
fp = path.Join(runner.Cwd, "integrations")
|
||||
}
|
||||
|
||||
cate := ginx.UrlParamStr(c, "cate")
|
||||
iconPath := fp + "/" + cate + "/icon/" + ginx.UrlParamStr(c, "name")
|
||||
c.File(path.Join(iconPath))
|
||||
}
|
||||
|
||||
@@ -123,6 +123,11 @@ func (rt *Router) busiGroupGets(c *gin.Context) {
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
func (rt *Router) busiGroupGetsByService(c *gin.Context) {
|
||||
lst, err := models.BusiGroupGetAll(rt.Ctx)
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
// 这个接口只有在活跃告警页面才调用,获取各个BG的活跃告警数量
|
||||
func (rt *Router) busiGroupAlertingsGets(c *gin.Context) {
|
||||
ids := ginx.QueryStr(c, "ids", "")
|
||||
|
||||
@@ -20,6 +20,11 @@ func (rt *Router) configGet(c *gin.Context) {
|
||||
ginx.NewRender(c).Data(configs, err)
|
||||
}
|
||||
|
||||
func (rt *Router) configGetByKey(c *gin.Context) {
|
||||
config, err := models.ConfigsGet(rt.Ctx, ginx.QueryStr(c, "key"))
|
||||
ginx.NewRender(c).Data(config, err)
|
||||
}
|
||||
|
||||
func (rt *Router) configsDel(c *gin.Context) {
|
||||
var f idsForm
|
||||
ginx.BindJSON(c, &f)
|
||||
|
||||
@@ -1,10 +1,17 @@
|
||||
package router
|
||||
|
||||
import (
|
||||
"crypto/tls"
|
||||
"fmt"
|
||||
"net/http"
|
||||
"net/url"
|
||||
"strings"
|
||||
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
|
||||
"github.com/gin-gonic/gin"
|
||||
"github.com/toolkits/pkg/ginx"
|
||||
"github.com/toolkits/pkg/logger"
|
||||
)
|
||||
|
||||
func (rt *Router) pluginList(c *gin.Context) {
|
||||
@@ -29,6 +36,34 @@ func (rt *Router) datasourceList(c *gin.Context) {
|
||||
Render(c, list, err)
|
||||
}
|
||||
|
||||
func (rt *Router) datasourceGetsByService(c *gin.Context) {
|
||||
typ := ginx.QueryStr(c, "typ", "")
|
||||
lst, err := models.GetDatasourcesGetsBy(rt.Ctx, typ, "", "", "")
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
type datasourceBrief struct {
|
||||
Id int64 `json:"id"`
|
||||
Name string `json:"name"`
|
||||
PluginType string `json:"plugin_type"`
|
||||
}
|
||||
|
||||
func (rt *Router) datasourceBriefs(c *gin.Context) {
|
||||
var dss []datasourceBrief
|
||||
list, err := models.GetDatasourcesGetsBy(rt.Ctx, "", "", "", "")
|
||||
ginx.Dangerous(err)
|
||||
|
||||
for i := range list {
|
||||
dss = append(dss, datasourceBrief{
|
||||
Id: list[i].Id,
|
||||
Name: list[i].Name,
|
||||
PluginType: list[i].PluginType,
|
||||
})
|
||||
}
|
||||
|
||||
ginx.NewRender(c).Data(dss, err)
|
||||
}
|
||||
|
||||
func (rt *Router) datasourceUpsert(c *gin.Context) {
|
||||
var req models.Datasource
|
||||
ginx.BindJSON(c, &req)
|
||||
@@ -37,6 +72,13 @@ func (rt *Router) datasourceUpsert(c *gin.Context) {
|
||||
|
||||
var err error
|
||||
var count int64
|
||||
|
||||
err = DatasourceCheck(req)
|
||||
if err != nil {
|
||||
Dangerous(c, err)
|
||||
return
|
||||
}
|
||||
|
||||
if req.Id == 0 {
|
||||
req.CreatedBy = username
|
||||
req.Status = "enabled"
|
||||
@@ -52,12 +94,74 @@ func (rt *Router) datasourceUpsert(c *gin.Context) {
|
||||
}
|
||||
err = req.Add(rt.Ctx)
|
||||
} else {
|
||||
err = req.Update(rt.Ctx, "name", "description", "cluster_name", "settings", "http", "auth", "status", "updated_by", "updated_at")
|
||||
err = req.Update(rt.Ctx, "name", "description", "cluster_name", "settings", "http", "auth", "updated_by", "updated_at")
|
||||
}
|
||||
|
||||
Render(c, nil, err)
|
||||
}
|
||||
|
||||
func DatasourceCheck(ds models.Datasource) error {
|
||||
if ds.HTTPJson.Url == "" {
|
||||
return fmt.Errorf("url is empty")
|
||||
}
|
||||
|
||||
client := &http.Client{
|
||||
Transport: &http.Transport{
|
||||
TLSClientConfig: &tls.Config{
|
||||
InsecureSkipVerify: ds.HTTPJson.TLS.SkipTlsVerify,
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
fullURL := ds.HTTPJson.Url
|
||||
req, err := http.NewRequest("GET", fullURL, nil)
|
||||
if err != nil {
|
||||
logger.Errorf("Error creating request: %v", err)
|
||||
return fmt.Errorf("request url:%s failed", fullURL)
|
||||
}
|
||||
|
||||
if ds.PluginType == models.PROMETHEUS {
|
||||
subPath := "/api/v1/query"
|
||||
query := url.Values{}
|
||||
if strings.Contains(fullURL, "loki") {
|
||||
subPath = "/api/v1/labels"
|
||||
query.Add("start", "1")
|
||||
query.Add("end", "2")
|
||||
} else {
|
||||
query.Add("query", "1+1")
|
||||
}
|
||||
fullURL = fmt.Sprintf("%s%s?%s", ds.HTTPJson.Url, subPath, query.Encode())
|
||||
|
||||
req, err = http.NewRequest("POST", fullURL, nil)
|
||||
if err != nil {
|
||||
logger.Errorf("Error creating request: %v", err)
|
||||
return fmt.Errorf("request url:%s failed", fullURL)
|
||||
}
|
||||
}
|
||||
|
||||
if ds.AuthJson.BasicAuthUser != "" {
|
||||
req.SetBasicAuth(ds.AuthJson.BasicAuthUser, ds.AuthJson.BasicAuthPassword)
|
||||
}
|
||||
|
||||
for k, v := range ds.HTTPJson.Headers {
|
||||
req.Header.Set(k, v)
|
||||
}
|
||||
|
||||
resp, err := client.Do(req)
|
||||
if err != nil {
|
||||
logger.Errorf("Error making request: %v\n", err)
|
||||
return fmt.Errorf("request url:%s failed", fullURL)
|
||||
}
|
||||
defer resp.Body.Close()
|
||||
|
||||
if resp.StatusCode != 200 {
|
||||
logger.Errorf("Error making request: %v\n", resp.StatusCode)
|
||||
return fmt.Errorf("request url:%s failed code:%d", fullURL, resp.StatusCode)
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func (rt *Router) datasourceGet(c *gin.Context) {
|
||||
var req models.Datasource
|
||||
ginx.BindJSON(c, &req)
|
||||
@@ -81,6 +185,13 @@ func (rt *Router) datasourceDel(c *gin.Context) {
|
||||
Render(c, nil, err)
|
||||
}
|
||||
|
||||
func (rt *Router) getDatasourceIds(c *gin.Context) {
|
||||
name := ginx.QueryStr(c, "name")
|
||||
datasourceIds, err := models.GetDatasourceIdsByEngineName(rt.Ctx, name)
|
||||
|
||||
ginx.NewRender(c).Data(datasourceIds, err)
|
||||
}
|
||||
|
||||
func Username(c *gin.Context) string {
|
||||
|
||||
return c.MustGet("username").(string)
|
||||
|
||||
@@ -17,6 +17,41 @@ import (
|
||||
|
||||
const defaultLimit = 300
|
||||
|
||||
func (rt *Router) statistic(c *gin.Context) {
|
||||
name := ginx.QueryStr(c, "name")
|
||||
var model interface{}
|
||||
var err error
|
||||
var statistics *models.Statistics
|
||||
switch name {
|
||||
case "alert_mute":
|
||||
model = models.AlertMute{}
|
||||
case "alert_rule":
|
||||
model = models.AlertRule{}
|
||||
case "alert_subscribe":
|
||||
model = models.AlertSubscribe{}
|
||||
case "busi_group":
|
||||
model = models.BusiGroup{}
|
||||
case "recording_rule":
|
||||
model = models.RecordingRule{}
|
||||
case "target":
|
||||
model = models.Target{}
|
||||
case "user":
|
||||
model = models.User{}
|
||||
case "user_group":
|
||||
model = models.UserGroup{}
|
||||
case "datasource":
|
||||
// datasource update_at is different from others
|
||||
statistics, err = models.DatasourceStatistics(rt.Ctx)
|
||||
ginx.NewRender(c).Data(statistics, err)
|
||||
return
|
||||
default:
|
||||
ginx.Bomb(http.StatusBadRequest, "invalid name")
|
||||
}
|
||||
|
||||
statistics, err = models.StatisticsGet(rt.Ctx, model)
|
||||
ginx.NewRender(c).Data(statistics, err)
|
||||
}
|
||||
|
||||
func queryDatasourceIds(c *gin.Context) []int64 {
|
||||
datasourceIds := ginx.QueryStr(c, "datasource_ids", "")
|
||||
datasourceIds = strings.ReplaceAll(datasourceIds, ",", " ")
|
||||
|
||||
@@ -36,6 +36,17 @@ func (rt *Router) heartbeat(c *gin.Context) {
|
||||
ginx.Dangerous(err)
|
||||
|
||||
req.Offset = (time.Now().UnixMilli() - req.UnixTime)
|
||||
req.RemoteAddr = c.ClientIP()
|
||||
rt.MetaSet.Set(req.Hostname, req)
|
||||
ginx.NewRender(c).Message(nil)
|
||||
|
||||
gid := ginx.QueryInt64(c, "gid", 0)
|
||||
|
||||
if gid != 0 {
|
||||
target, has := rt.TargetCache.Get(req.Hostname)
|
||||
if has && target.GroupId != gid {
|
||||
err = models.TargetUpdateBgid(rt.Ctx, []string{req.Hostname}, gid, false)
|
||||
}
|
||||
}
|
||||
|
||||
ginx.NewRender(c).Message(err)
|
||||
}
|
||||
|
||||
@@ -40,7 +40,7 @@ func (rt *Router) loginPost(c *gin.Context) {
|
||||
ginx.NewRender(c).Message(err)
|
||||
return
|
||||
}
|
||||
user.RolesLst = rt.Sso.LDAP.DefaultRoles
|
||||
user.RolesLst = strings.Fields(user.Roles)
|
||||
} else {
|
||||
ginx.NewRender(c).Message(err)
|
||||
return
|
||||
|
||||
@@ -21,7 +21,7 @@ func (rt *Router) alertMuteGetsByBG(c *gin.Context) {
|
||||
|
||||
func (rt *Router) alertMuteGets(c *gin.Context) {
|
||||
prods := strings.Fields(ginx.QueryStr(c, "prods", ""))
|
||||
bgid := ginx.QueryInt64(c, "bgid", 0)
|
||||
bgid := ginx.QueryInt64(c, "bgid", -1)
|
||||
query := ginx.QueryStr(c, "query", "")
|
||||
lst, err := models.AlertMuteGets(rt.Ctx, prods, bgid, query)
|
||||
|
||||
|
||||
@@ -5,6 +5,7 @@ import (
|
||||
|
||||
"github.com/ccfos/nightingale/v6/alert/aconf"
|
||||
"github.com/ccfos/nightingale/v6/alert/sender"
|
||||
"github.com/ccfos/nightingale/v6/memsto"
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
"github.com/pelletier/go-toml/v2"
|
||||
|
||||
@@ -29,9 +30,12 @@ func (rt *Router) webhookPuts(c *gin.Context) {
|
||||
var webhooks []models.Webhook
|
||||
ginx.BindJSON(c, &webhooks)
|
||||
for i := 0; i < len(webhooks); i++ {
|
||||
for k, v := range webhooks[i].HeaderMap {
|
||||
webhooks[i].Headers = append(webhooks[i].Headers, k)
|
||||
webhooks[i].Headers = append(webhooks[i].Headers, v)
|
||||
webhooks[i].Headers = []string{}
|
||||
if len(webhooks[i].HeaderMap) > 0 {
|
||||
for k, v := range webhooks[i].HeaderMap {
|
||||
webhooks[i].Headers = append(webhooks[i].Headers, k)
|
||||
webhooks[i].Headers = append(webhooks[i].Headers, v)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -137,32 +141,15 @@ func (rt *Router) notifyContactPuts(c *gin.Context) {
|
||||
ginx.NewRender(c).Message(models.ConfigsSet(rt.Ctx, models.NOTIFYCONTACT, string(data)))
|
||||
}
|
||||
|
||||
const DefaultSMTP = `
|
||||
Host = ""
|
||||
Port = 994
|
||||
User = "username"
|
||||
Pass = "password"
|
||||
From = "username@163.com"
|
||||
InsecureSkipVerify = true
|
||||
Batch = 5
|
||||
`
|
||||
|
||||
const DefaultIbex = `
|
||||
Address = "http://127.0.0.1:10090"
|
||||
BasicAuthUser = "ibex"
|
||||
BasicAuthPass = "ibex"
|
||||
Timeout = 3000
|
||||
`
|
||||
|
||||
func (rt *Router) notifyConfigGet(c *gin.Context) {
|
||||
key := ginx.QueryStr(c, "ckey")
|
||||
cval, err := models.ConfigsGet(rt.Ctx, key)
|
||||
if cval == "" {
|
||||
switch key {
|
||||
case models.IBEX:
|
||||
cval = DefaultIbex
|
||||
cval = memsto.DefaultIbex
|
||||
case models.SMTP:
|
||||
cval = DefaultSMTP
|
||||
cval = memsto.DefaultSMTP
|
||||
}
|
||||
}
|
||||
ginx.NewRender(c).Data(cval, err)
|
||||
|
||||
@@ -3,7 +3,9 @@ package router
|
||||
import (
|
||||
"bytes"
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"html/template"
|
||||
"strings"
|
||||
|
||||
"github.com/ccfos/nightingale/v6/center/cconf"
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
@@ -22,6 +24,11 @@ func (rt *Router) notifyTplUpdateContent(c *gin.Context) {
|
||||
var f models.NotifyTpl
|
||||
ginx.BindJSON(c, &f)
|
||||
|
||||
if err := templateValidate(f); err != nil {
|
||||
ginx.NewRender(c).Message(err.Error())
|
||||
return
|
||||
}
|
||||
|
||||
ginx.NewRender(c).Message(f.UpdateContent(rt.Ctx))
|
||||
}
|
||||
|
||||
@@ -29,9 +36,32 @@ func (rt *Router) notifyTplUpdate(c *gin.Context) {
|
||||
var f models.NotifyTpl
|
||||
ginx.BindJSON(c, &f)
|
||||
|
||||
if err := templateValidate(f); err != nil {
|
||||
ginx.NewRender(c).Message(err.Error())
|
||||
return
|
||||
}
|
||||
|
||||
ginx.NewRender(c).Message(f.Update(rt.Ctx))
|
||||
}
|
||||
|
||||
func templateValidate(f models.NotifyTpl) error {
|
||||
if f.Content == "" {
|
||||
return nil
|
||||
}
|
||||
|
||||
var defs = []string{
|
||||
"{{$labels := .TagsMap}}",
|
||||
"{{$value := .TriggerValue}}",
|
||||
}
|
||||
text := strings.Join(append(defs, f.Content), "")
|
||||
|
||||
if _, err := template.New(f.Channel).Funcs(tplx.TemplateFuncMap).Parse(text); err != nil {
|
||||
return fmt.Errorf("notify template verify illegal:%s", err.Error())
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func (rt *Router) notifyTplPreview(c *gin.Context) {
|
||||
var event models.AlertCurEvent
|
||||
err := json.Unmarshal([]byte(cconf.EVENT_EXAMPLE), &event)
|
||||
@@ -43,9 +73,29 @@ func (rt *Router) notifyTplPreview(c *gin.Context) {
|
||||
var f models.NotifyTpl
|
||||
ginx.BindJSON(c, &f)
|
||||
|
||||
tpl, err := template.New(f.Channel).Funcs(tplx.TemplateFuncMap).Parse(f.Content)
|
||||
var defs = []string{
|
||||
"{{$labels := .TagsMap}}",
|
||||
"{{$value := .TriggerValue}}",
|
||||
}
|
||||
text := strings.Join(append(defs, f.Content), "")
|
||||
tpl, err := template.New(f.Channel).Funcs(tplx.TemplateFuncMap).Parse(text)
|
||||
ginx.Dangerous(err)
|
||||
|
||||
event.TagsMap = make(map[string]string)
|
||||
for i := 0; i < len(event.TagsJSON); i++ {
|
||||
pair := strings.TrimSpace(event.TagsJSON[i])
|
||||
if pair == "" {
|
||||
continue
|
||||
}
|
||||
|
||||
arr := strings.Split(pair, "=")
|
||||
if len(arr) != 2 {
|
||||
continue
|
||||
}
|
||||
|
||||
event.TagsMap[arr[0]] = arr[1]
|
||||
}
|
||||
|
||||
var body bytes.Buffer
|
||||
var ret string
|
||||
if err := tpl.Execute(&body, event); err != nil {
|
||||
|
||||
@@ -2,6 +2,7 @@ package router
|
||||
|
||||
import (
|
||||
"context"
|
||||
"crypto/tls"
|
||||
"net"
|
||||
"net/http"
|
||||
"net/http/httputil"
|
||||
@@ -139,7 +140,8 @@ func (rt *Router) dsProxy(c *gin.Context) {
|
||||
}
|
||||
|
||||
transport := &http.Transport{
|
||||
Proxy: http.ProxyFromEnvironment,
|
||||
TLSClientConfig: &tls.Config{InsecureSkipVerify: ds.HTTPJson.TLS.SkipTlsVerify},
|
||||
Proxy: http.ProxyFromEnvironment,
|
||||
DialContext: (&net.Dialer{
|
||||
Timeout: time.Duration(ds.HTTPJson.DialTimeout) * time.Millisecond,
|
||||
}).DialContext,
|
||||
|
||||
@@ -1,7 +1,10 @@
|
||||
package router
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"net/http"
|
||||
"strconv"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
@@ -16,6 +19,11 @@ func (rt *Router) recordingRuleGets(c *gin.Context) {
|
||||
ginx.NewRender(c).Data(ars, err)
|
||||
}
|
||||
|
||||
func (rt *Router) recordingRuleGetsByService(c *gin.Context) {
|
||||
ars, err := models.RecordingRuleEnabledGets(rt.Ctx)
|
||||
ginx.NewRender(c).Data(ars, err)
|
||||
}
|
||||
|
||||
func (rt *Router) recordingRuleGet(c *gin.Context) {
|
||||
rrid := ginx.UrlParamInt64(c, "rrid")
|
||||
|
||||
@@ -104,6 +112,25 @@ func (rt *Router) recordingRulePutFields(c *gin.Context) {
|
||||
f.Fields["update_by"] = c.MustGet("username").(string)
|
||||
f.Fields["update_at"] = time.Now().Unix()
|
||||
|
||||
if _, ok := f.Fields["datasource_ids"]; ok {
|
||||
// datasource_ids = "1 2 3"
|
||||
idsStr := strings.Fields(f.Fields["datasource_ids"].(string))
|
||||
ids := make([]int64, 0)
|
||||
for _, idStr := range idsStr {
|
||||
id, err := strconv.ParseInt(idStr, 10, 64)
|
||||
if err != nil {
|
||||
ginx.Bomb(http.StatusBadRequest, "datasource_ids error")
|
||||
}
|
||||
ids = append(ids, id)
|
||||
}
|
||||
|
||||
bs, err := json.Marshal(ids)
|
||||
if err != nil {
|
||||
ginx.Bomb(http.StatusBadRequest, "datasource_ids error")
|
||||
}
|
||||
f.Fields["datasource_ids"] = string(bs)
|
||||
}
|
||||
|
||||
for i := 0; i < len(f.Ids); i++ {
|
||||
ar, err := models.RecordingRuleGetById(rt.Ctx, f.Ids[i])
|
||||
ginx.Dangerous(err)
|
||||
|
||||
@@ -83,3 +83,18 @@ func (rt *Router) roleGets(c *gin.Context) {
|
||||
lst, err := models.RoleGetsAll(rt.Ctx)
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
func (rt *Router) allPerms(c *gin.Context) {
|
||||
roles, err := models.RoleGetsAll(rt.Ctx)
|
||||
ginx.Dangerous(err)
|
||||
m := make(map[string][]string)
|
||||
for _, r := range roles {
|
||||
lst, err := models.OperationsOfRole(rt.Ctx, strings.Fields(r.Name))
|
||||
if err != nil {
|
||||
continue
|
||||
}
|
||||
m[r.Name] = lst
|
||||
}
|
||||
|
||||
ginx.NewRender(c).Data(m, err)
|
||||
}
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
package router
|
||||
|
||||
import (
|
||||
"time"
|
||||
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
|
||||
"github.com/gin-gonic/gin"
|
||||
@@ -16,3 +18,17 @@ func (rt *Router) serverClustersGet(c *gin.Context) {
|
||||
list, err := models.AlertingEngineGetsClusters(rt.Ctx, "")
|
||||
ginx.NewRender(c).Data(list, err)
|
||||
}
|
||||
|
||||
func (rt *Router) serverHeartbeat(c *gin.Context) {
|
||||
var req models.HeartbeatInfo
|
||||
ginx.BindJSON(c, &req)
|
||||
err := models.AlertingEngineHeartbeatWithCluster(rt.Ctx, req.Instance, req.EngineCluster, req.DatasourceId)
|
||||
ginx.NewRender(c).Message(err)
|
||||
}
|
||||
|
||||
func (rt *Router) serversActive(c *gin.Context) {
|
||||
datasourceId := ginx.QueryInt64(c, "dsid")
|
||||
|
||||
servers, err := models.AlertingEngineGetsInstances(rt.Ctx, "datasource_id = ? and clock > ?", datasourceId, time.Now().Unix()-30)
|
||||
ginx.NewRender(c).Data(servers, err)
|
||||
}
|
||||
|
||||
@@ -9,6 +9,7 @@ import (
|
||||
"time"
|
||||
|
||||
"github.com/ccfos/nightingale/v6/models"
|
||||
"github.com/ccfos/nightingale/v6/storage"
|
||||
|
||||
"github.com/gin-gonic/gin"
|
||||
"github.com/prometheus/common/model"
|
||||
@@ -64,13 +65,13 @@ func (rt *Router) targetGets(c *gin.Context) {
|
||||
|
||||
if len(keys) > 0 {
|
||||
metaMap := make(map[string]*models.HostMeta)
|
||||
vals := rt.Redis.MGet(context.Background(), keys...).Val()
|
||||
vals := storage.MGet(context.Background(), rt.Redis, keys)
|
||||
for _, value := range vals {
|
||||
var meta models.HostMeta
|
||||
if value == nil {
|
||||
continue
|
||||
}
|
||||
err := json.Unmarshal([]byte(value.(string)), &meta)
|
||||
err := json.Unmarshal(value, &meta)
|
||||
if err != nil {
|
||||
logger.Warningf("unmarshal %v host meta failed: %v", value, err)
|
||||
continue
|
||||
@@ -79,11 +80,12 @@ func (rt *Router) targetGets(c *gin.Context) {
|
||||
}
|
||||
|
||||
for i := 0; i < len(list); i++ {
|
||||
if now.Unix()-list[i].UpdateAt < 120 {
|
||||
list[i].TargetUp = 1
|
||||
}
|
||||
|
||||
if meta, ok := metaMap[list[i].Ident]; ok {
|
||||
list[i].FillMeta(meta)
|
||||
if now.Unix()-list[i].UpdateAt < 120 {
|
||||
list[i].TargetUp = 1
|
||||
}
|
||||
} else {
|
||||
// 未上报过元数据的主机,cpuNum默认为-1, 用于前端展示 unknown
|
||||
list[i].CpuNum = -1
|
||||
@@ -99,6 +101,11 @@ func (rt *Router) targetGets(c *gin.Context) {
|
||||
}, nil)
|
||||
}
|
||||
|
||||
func (rt *Router) targetGetsByService(c *gin.Context) {
|
||||
lst, err := models.TargetGetsAll(rt.Ctx)
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
func (rt *Router) targetGetTags(c *gin.Context) {
|
||||
idents := ginx.QueryStr(c, "idents", "")
|
||||
idents = strings.ReplaceAll(idents, ",", " ")
|
||||
|
||||
@@ -120,6 +120,12 @@ func (f *taskForm) HandleFH(fh string) {
|
||||
f.Title = f.Title + " FH: " + fh
|
||||
}
|
||||
|
||||
func (rt *Router) taskRecordAdd(c *gin.Context) {
|
||||
var f *models.TaskRecord
|
||||
ginx.BindJSON(c, &f)
|
||||
ginx.NewRender(c).Message(f.Add(rt.Ctx))
|
||||
}
|
||||
|
||||
func (rt *Router) taskAdd(c *gin.Context) {
|
||||
var f taskForm
|
||||
ginx.BindJSON(c, &f)
|
||||
|
||||
@@ -12,19 +12,8 @@ import (
|
||||
)
|
||||
|
||||
func (rt *Router) userFindAll(c *gin.Context) {
|
||||
limit := ginx.QueryInt(c, "limit", 20)
|
||||
query := ginx.QueryStr(c, "query", "")
|
||||
|
||||
total, err := models.UserTotal(rt.Ctx, query)
|
||||
ginx.Dangerous(err)
|
||||
|
||||
list, err := models.UserGets(rt.Ctx, query, limit, ginx.Offset(c, limit))
|
||||
ginx.Dangerous(err)
|
||||
|
||||
ginx.NewRender(c).Data(gin.H{
|
||||
"list": list,
|
||||
"total": total,
|
||||
}, nil)
|
||||
list, err := models.UserGetAll(rt.Ctx)
|
||||
ginx.NewRender(c).Data(list, err)
|
||||
}
|
||||
|
||||
func (rt *Router) userGets(c *gin.Context) {
|
||||
|
||||
@@ -29,6 +29,17 @@ func (rt *Router) userGroupGets(c *gin.Context) {
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
func (rt *Router) userGroupGetsByService(c *gin.Context) {
|
||||
lst, err := models.UserGroupGetAll(rt.Ctx)
|
||||
ginx.NewRender(c).Data(lst, err)
|
||||
}
|
||||
|
||||
// user group member get by service
|
||||
func (rt *Router) userGroupMemberGetsByService(c *gin.Context) {
|
||||
members, err := models.UserGroupMemberGetAll(rt.Ctx)
|
||||
ginx.NewRender(c).Data(members, err)
|
||||
}
|
||||
|
||||
type userGroupForm struct {
|
||||
Name string `json:"name" binding:"required"`
|
||||
Note string `json:"note"`
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
# v5 升级 v6 手册
|
||||
0. 操作之前,记得备注下数据库!
|
||||
|
||||
1. 解压 n9e 安装包
|
||||
2. 导入 upgrade.sql 到 n9e_v5 数据库
|
||||
1. 需要先将你正在使用的夜莺数据源表结构更新到和 v5.15.0 一致,[release](https://github.com/ccfos/nightingale/releases) 页面有每个版本表结构的更新说明,可以根据你正在使用的版本,按照说明,逐个执行的更新表结构的语句
|
||||
|
||||
2. 解压 n9e 安装包,导入 upgrade.sql 到 n9e_v5 数据库
|
||||
```
|
||||
mysql -h 127.0.0.1 -u root -p1234 < cli/upgrade/upgrade.sql
|
||||
```
|
||||
@@ -16,4 +18,4 @@ mysql -h 127.0.0.1 -u root -p1234 < cli/upgrade/upgrade.sql
|
||||
nohup ./n9e &> n9e.log &
|
||||
```
|
||||
|
||||
5. n9e 监听的端口为 17000,如果想使用之前的端口,可以在配置文件中将端口改为 18000
|
||||
5. n9e 监听的端口为 17000,需要将之前的 web 端口和数据上报的端口,都调整为 17000
|
||||
@@ -18,7 +18,7 @@ func Upgrade(configFile string) error {
|
||||
return err
|
||||
}
|
||||
|
||||
ctx := ctx.NewContext(context.Background(), db)
|
||||
ctx := ctx.NewContext(context.Background(), db, false)
|
||||
for _, cluster := range config.Clusters {
|
||||
count, err := models.GetDatasourcesCountBy(ctx, "", "", cluster.Name)
|
||||
if err != nil {
|
||||
|
||||
@@ -19,7 +19,7 @@ alter table `alert_rule` add rule_config text not null comment 'rule_config';
|
||||
alter table `alert_rule` add annotations text not null comment 'annotations';
|
||||
|
||||
alter table `alert_mute` add datasource_ids varchar(255) not null default '';
|
||||
alter table `alert_mute` add periodic_mutes varchar(4096) not null default '';
|
||||
alter table `alert_mute` add periodic_mutes varchar(4096) not null default '[]';
|
||||
alter table `alert_mute` add mute_time_type tinyint(1) not null default 0;
|
||||
|
||||
alter table `alert_subscribe` add datasource_ids varchar(255) not null default '';
|
||||
@@ -41,6 +41,9 @@ alter table `alert_his_event` add annotations text not null comment 'annotations
|
||||
alter table `alert_his_event` add rule_config text not null comment 'rule_config';
|
||||
|
||||
alter table `alerting_engines` add datasource_id bigint unsigned not null default 0;
|
||||
alter table `alerting_engines` change cluster engine_cluster varchar(128) not null default '' comment 'n9e engine cluster';
|
||||
|
||||
alter table `task_record` add event_id bigint not null comment 'event id' default 0;
|
||||
|
||||
CREATE TABLE `datasource`
|
||||
(
|
||||
@@ -81,7 +84,7 @@ CREATE TABLE `notify_tpl` (
|
||||
|
||||
CREATE TABLE `sso_config` (
|
||||
`id` bigint unsigned not null auto_increment,
|
||||
`name` varchar(255) not null,
|
||||
`name` varchar(191) not null,
|
||||
`content` text not null,
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY (`name`)
|
||||
|
||||
61
conf/conf.go
61
conf/conf.go
@@ -2,6 +2,7 @@ package conf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"net"
|
||||
"os"
|
||||
"strings"
|
||||
|
||||
@@ -13,20 +14,28 @@ import (
|
||||
"github.com/ccfos/nightingale/v6/pkg/ormx"
|
||||
"github.com/ccfos/nightingale/v6/pushgw/pconf"
|
||||
"github.com/ccfos/nightingale/v6/storage"
|
||||
|
||||
"github.com/gin-gonic/gin"
|
||||
)
|
||||
|
||||
type ConfigType struct {
|
||||
Global GlobalConfig
|
||||
Log logx.Config
|
||||
HTTP httpx.Config
|
||||
DB ormx.DBConfig
|
||||
Redis storage.RedisConfig
|
||||
Global GlobalConfig
|
||||
Log logx.Config
|
||||
HTTP httpx.Config
|
||||
DB ormx.DBConfig
|
||||
Redis storage.RedisConfig
|
||||
CenterApi CenterApi
|
||||
|
||||
Pushgw pconf.Pushgw
|
||||
Alert aconf.Alert
|
||||
Center cconf.Center
|
||||
}
|
||||
|
||||
type CenterApi struct {
|
||||
Addrs []string
|
||||
BasicAuth gin.Accounts
|
||||
}
|
||||
|
||||
type GlobalConfig struct {
|
||||
RunMode string
|
||||
}
|
||||
@@ -49,28 +58,36 @@ func InitConfig(configDir, cryptoKey string) (*ConfigType, error) {
|
||||
|
||||
if config.Alert.Heartbeat.IP == "" {
|
||||
// auto detect
|
||||
// config.Alert.Heartbeat.IP = fmt.Sprint(GetOutboundIP())
|
||||
// 自动获取IP在有些环境下容易出错,这里用hostname+pid来作唯一标识
|
||||
config.Alert.Heartbeat.IP = fmt.Sprint(GetOutboundIP())
|
||||
if config.Alert.Heartbeat.IP == "" {
|
||||
hostname, err := os.Hostname()
|
||||
if err != nil {
|
||||
fmt.Println("failed to get hostname:", err)
|
||||
os.Exit(1)
|
||||
}
|
||||
|
||||
hostname, err := os.Hostname()
|
||||
if err != nil {
|
||||
fmt.Println("failed to get hostname:", err)
|
||||
os.Exit(1)
|
||||
if strings.Contains(hostname, "localhost") {
|
||||
fmt.Println("Warning! hostname contains substring localhost, setting a more unique hostname is recommended")
|
||||
}
|
||||
|
||||
config.Alert.Heartbeat.IP = hostname
|
||||
}
|
||||
|
||||
if strings.Contains(hostname, "localhost") {
|
||||
fmt.Println("Warning! hostname contains substring localhost, setting a more unique hostname is recommended")
|
||||
}
|
||||
|
||||
config.Alert.Heartbeat.IP = hostname
|
||||
|
||||
// if config.Alert.Heartbeat.IP == "" {
|
||||
// fmt.Println("heartbeat ip auto got is blank")
|
||||
// os.Exit(1)
|
||||
// }
|
||||
}
|
||||
|
||||
config.Alert.Heartbeat.Endpoint = fmt.Sprintf("%s:%d", config.Alert.Heartbeat.IP, config.HTTP.Port)
|
||||
|
||||
return config, nil
|
||||
}
|
||||
|
||||
func GetOutboundIP() net.IP {
|
||||
conn, err := net.Dial("udp", "223.5.5.5:80")
|
||||
if err != nil {
|
||||
fmt.Println("auto get outbound ip fail:", err)
|
||||
return []byte{}
|
||||
}
|
||||
defer conn.Close()
|
||||
|
||||
localAddr := conn.LocalAddr().(*net.UDPAddr)
|
||||
|
||||
return localAddr.IP
|
||||
}
|
||||
|
||||
@@ -14,39 +14,22 @@ func decryptConfig(config *ConfigType, cryptoKey string) error {
|
||||
|
||||
config.DB.DSN = decryptDsn
|
||||
|
||||
for k := range config.HTTP.Alert.BasicAuth {
|
||||
decryptPwd, err := secu.DealWithDecrypt(config.HTTP.Alert.BasicAuth[k], cryptoKey)
|
||||
for k := range config.HTTP.APIForService.BasicAuth {
|
||||
decryptPwd, err := secu.DealWithDecrypt(config.HTTP.APIForService.BasicAuth[k], cryptoKey)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed to decrypt http basic auth password: %s", err)
|
||||
}
|
||||
|
||||
config.HTTP.Alert.BasicAuth[k] = decryptPwd
|
||||
config.HTTP.APIForService.BasicAuth[k] = decryptPwd
|
||||
}
|
||||
|
||||
for k := range config.HTTP.Pushgw.BasicAuth {
|
||||
decryptPwd, err := secu.DealWithDecrypt(config.HTTP.Pushgw.BasicAuth[k], cryptoKey)
|
||||
for k := range config.HTTP.APIForAgent.BasicAuth {
|
||||
decryptPwd, err := secu.DealWithDecrypt(config.HTTP.APIForAgent.BasicAuth[k], cryptoKey)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed to decrypt http basic auth password: %s", err)
|
||||
}
|
||||
|
||||
config.HTTP.Pushgw.BasicAuth[k] = decryptPwd
|
||||
}
|
||||
|
||||
for k := range config.HTTP.Heartbeat.BasicAuth {
|
||||
decryptPwd, err := secu.DealWithDecrypt(config.HTTP.Heartbeat.BasicAuth[k], cryptoKey)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed to decrypt http basic auth password: %s", err)
|
||||
}
|
||||
|
||||
config.HTTP.Heartbeat.BasicAuth[k] = decryptPwd
|
||||
}
|
||||
|
||||
for k := range config.HTTP.Service.BasicAuth {
|
||||
decryptPwd, err := secu.DealWithDecrypt(config.HTTP.Service.BasicAuth[k], cryptoKey)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed to decrypt http basic auth password: %s", err)
|
||||
}
|
||||
config.HTTP.Service.BasicAuth[k] = decryptPwd
|
||||
config.HTTP.APIForAgent.BasicAuth[k] = decryptPwd
|
||||
}
|
||||
|
||||
for i, v := range config.Pushgw.Writers {
|
||||
|
||||
@@ -15,24 +15,27 @@
|
||||
<img alt="GitHub forks" src="https://img.shields.io/github/forks/ccfos/nightingale">
|
||||
<a href="https://github.com/ccfos/nightingale/graphs/contributors">
|
||||
<img alt="GitHub contributors" src="https://img.shields.io/github/contributors-anon/ccfos/nightingale"/></a>
|
||||
<a href="https://n9e-talk.slack.com/">
|
||||
<img alt="GitHub contributors" src="https://img.shields.io/badge/join%20slack-%23n9e-brightgreen.svg"/></a>
|
||||
<img alt="License" src="https://img.shields.io/badge/license-Apache--2.0-blue"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<b>All-in-one</b> 的开源云原生监控系统 <br/>
|
||||
<b>All-in-one</b> 的开源观测平台 <br/>
|
||||
<b>开箱即用</b>,集数据采集、可视化、监控告警于一体 <br/>
|
||||
推荐升级您的 <b>Prometheus + AlertManager + Grafana</b> 组合方案到夜莺!
|
||||
推荐升级您的 <b>Prometheus + AlertManager + Grafana + ELK + Jaeger</b> 组合方案到夜莺!
|
||||
</p>
|
||||
|
||||
[English](./README.md) | [中文](./README_ZH.md)
|
||||
[English](./README_en.md) | [中文](./README.md)
|
||||
|
||||
|
||||
|
||||
## Highlighted Features
|
||||
## 功能和特点
|
||||
|
||||
- **开箱即用**
|
||||
- 支持 Docker、Helm Chart、云服务等多种部署方式,集数据采集、监控告警、可视化为一体,内置多种监控仪表盘、快捷视图、告警规则模板,导入即可快速使用,**大幅降低云原生监控系统的建设成本、学习成本、使用成本**;
|
||||
- **专业告警**
|
||||
- 可视化的告警配置和管理,支持丰富的告警规则,提供屏蔽规则、订阅规则的配置能力,支持告警多种送达渠道,支持告警自愈、告警事件管理等;
|
||||
- **推荐您使用夜莺的同时,无缝搭配[FlashDuty](https://flashcat.cloud/product/flashcat-duty/),实现告警聚合收敛、认领、升级、排班、协同,让告警的触达既高效,又确保告警处理不遗漏、做到件件有回响**。
|
||||
- **云原生**
|
||||
- 以交钥匙的方式快速构建企业级的云原生监控体系,支持 [Categraf](https://github.com/flashcatcloud/categraf)、Telegraf、Grafana-agent 等多种采集器,支持 Prometheus、VictoriaMetrics、M3DB、ElasticSearch、Jaeger 等多种数据源,兼容支持导入 Grafana 仪表盘,**与云原生生态无缝集成**;
|
||||
- **高性能 高可用**
|
||||
@@ -43,68 +46,85 @@
|
||||
- **开放社区**
|
||||
- 托管于[中国计算机学会开源发展委员会](https://www.ccf.org.cn/kyfzwyh/),有[快猫星云](https://flashcat.cloud)和众多公司的持续投入,和数千名社区用户的积极参与,以及夜莺监控项目清晰明确的定位,都保证了夜莺开源社区健康、长久的发展。活跃、专业的社区用户也在持续迭代和沉淀更多的最佳实践于产品中;
|
||||
|
||||
**如果您在使用 Prometheus 过程中,有以下的一个或者多个需求场景,推荐您无缝升级到夜莺**:
|
||||
## 使用场景
|
||||
1. **如果您希望在一个平台中,统一管理和查看 Metrics、Logging、Tracing 数据,推荐你使用夜莺**:
|
||||
- 请参考阅读:[不止于监控,夜莺 V6 全新升级为开源观测平台](http://flashcat.cloud/blog/nightingale-v6-release/)
|
||||
2. **如果您在使用 Prometheus 过程中,有以下的一个或者多个需求场景,推荐您无缝升级到夜莺**:
|
||||
- Prometheus、Alertmanager、Grafana 等多个系统较为割裂,缺乏统一视图,无法开箱即用;
|
||||
- 通过修改配置文件来管理 Prometheus、Alertmanager 的方式,学习曲线大,协同有难度;
|
||||
- 数据量过大而无法扩展您的 Prometheus 集群;
|
||||
- 生产环境运行多套 Prometheus 集群,面临管理和使用成本高的问题;
|
||||
3. **如果您在使用 Zabbix,有以下的场景,推荐您升级到夜莺**:
|
||||
- 监控的数据量太大,希望有更好的扩展解决方案;
|
||||
- 学习曲线高,多人多团队模式下,希望有更好的协同使用效率;
|
||||
- 微服务和云原生架构下,监控数据的生命周期多变、监控数据维度基数高,Zabbix 数据模型不易适配;
|
||||
- 了解更多Zabbix和夜莺监控的对比,推荐您进一步阅读[Zabbix 和夜莺监控选型对比](https://flashcat.cloud/blog/zabbx-vs-nightingale/)
|
||||
4. **如果您在使用 [Open-Falcon](https://github.com/open-falcon/falcon-plus),我们推荐您升级到夜莺:**
|
||||
- 关于 Open-Falcon 和夜莺的详细介绍,请参考阅读:[云原生监控的十个特点和趋势](http://flashcat.cloud/blog/10-trends-of-cloudnative-monitoring/)
|
||||
- 监控系统和可观测平台的区别,请参考阅读:[从监控系统到可观测平台,Gap有多大
|
||||
](https://flashcat.cloud/blog/gap-of-monitoring-to-o11y/)
|
||||
5. **我们推荐您使用 [Categraf](https://github.com/flashcatcloud/categraf) 作为首选的监控数据采集器**:
|
||||
- [Categraf](https://github.com/flashcatcloud/categraf) 是夜莺监控的默认采集器,采用开放插件机制和 All-in-one 的设计理念,同时支持 metric、log、trace、event 的采集。Categraf 不仅可以采集 CPU、内存、网络等系统层面的指标,也集成了众多开源组件的采集能力,支持K8s生态。Categraf 内置了对应的仪表盘和告警规则,开箱即用。
|
||||
|
||||
- Prometheus、Alertmanager、Grafana 等多个系统较为割裂,缺乏统一视图,无法开箱即用;
|
||||
- 通过修改配置文件来管理 Prometheus、Alertmanager 的方式,学习曲线大,协同有难度;
|
||||
- 数据量过大而无法扩展您的 Prometheus 集群;
|
||||
- 生产环境运行多套 Prometheus 集群,面临管理和使用成本高的问题;
|
||||
## 文档
|
||||
|
||||
**如果您在使用 Zabbix,有以下的场景,推荐您升级到夜莺**:
|
||||
[English Doc](https://n9e.github.io/) | [中文文档](https://flashcat.cloud/docs/)
|
||||
|
||||
- 监控的数据量太大,希望有更好的扩展解决方案;
|
||||
- 学习曲线高,多人多团队模式下,希望有更好的协同使用效率;
|
||||
- 微服务和云原生架构下,监控数据的生命周期多变、监控数据维度基数高,Zabbix 数据模型不易适配;
|
||||
|
||||
> 了解更多Zabbix和夜莺监控的对比,推荐您进一步阅读[《Zabbix 和夜莺监控选型对比》](https://flashcat.cloud/blog/zabbx-vs-nightingale/)
|
||||
|
||||
**如果您在使用 [Open-Falcon](https://github.com/open-falcon/falcon-plus),我们推荐您升级到夜莺:**
|
||||
|
||||
- 关于 Open-Falcon 和夜莺的详细介绍,请参考阅读:[《云原生监控的十个特点和趋势》](http://flashcat.cloud/blog/10-trends-of-cloudnative-monitoring/)
|
||||
|
||||
**我们推荐您使用 [Categraf](https://github.com/flashcatcloud/categraf) 作为首选的监控数据采集器**:
|
||||
|
||||
- [Categraf](https://github.com/flashcatcloud/categraf) 是夜莺监控的默认采集器,采用开放插件机制和 All-in-one 的设计理念,同时支持 metric、log、trace、event 的采集。Categraf 不仅可以采集 CPU、内存、网络等系统层面的指标,也集成了众多开源组件的采集能力,支持K8s生态。Categraf 内置了对应的仪表盘和告警规则,开箱即用。
|
||||
|
||||
|
||||
## Getting Started
|
||||
|
||||
[English Doc](https://n9e.github.io/) | [中文文档](http://n9e.flashcat.cloud/)
|
||||
|
||||
## Screenshots
|
||||
## 产品示意图
|
||||
|
||||
https://user-images.githubusercontent.com/792850/216888712-2565fcea-9df5-47bd-a49e-d60af9bd76e8.mp4
|
||||
|
||||
## Architecture
|
||||
|
||||
<img src="doc/img/arch-product.png" width="600">
|
||||
## 夜莺架构
|
||||
|
||||
夜莺监控可以接收各种采集器上报的监控数据(比如 [Categraf](https://github.com/flashcatcloud/categraf)、telegraf、grafana-agent、Prometheus),并写入多种流行的时序数据库中(可以支持Prometheus、M3DB、VictoriaMetrics、Thanos、TDEngine等),提供告警规则、屏蔽规则、订阅规则的配置能力,提供监控数据的查看能力,提供告警自愈机制(告警触发之后自动回调某个webhook地址或者执行某个脚本),提供历史告警事件的存储管理、分组查看的能力。
|
||||
|
||||
<img src="doc/img/arch-system.png" width="600">
|
||||
### 中心汇聚式部署方案
|
||||
|
||||
夜莺 v5 版本的设计非常简单,核心是 server 和 webapi 两个模块,webapi 无状态,放到中心端,承接前端请求,将用户配置写入数据库;server 是告警引擎和数据转发模块,一般随着时序库走,一个时序库就对应一套 server,每套 server 可以只用一个实例,也可以多个实例组成集群,server 可以接收 Categraf、Telegraf、Grafana-Agent、Datadog-Agent、Falcon-Plugins 上报的数据,写入后端时序库,周期性从数据库同步告警规则,然后查询时序库做告警判断。每套 server 依赖一个 redis。
|
||||
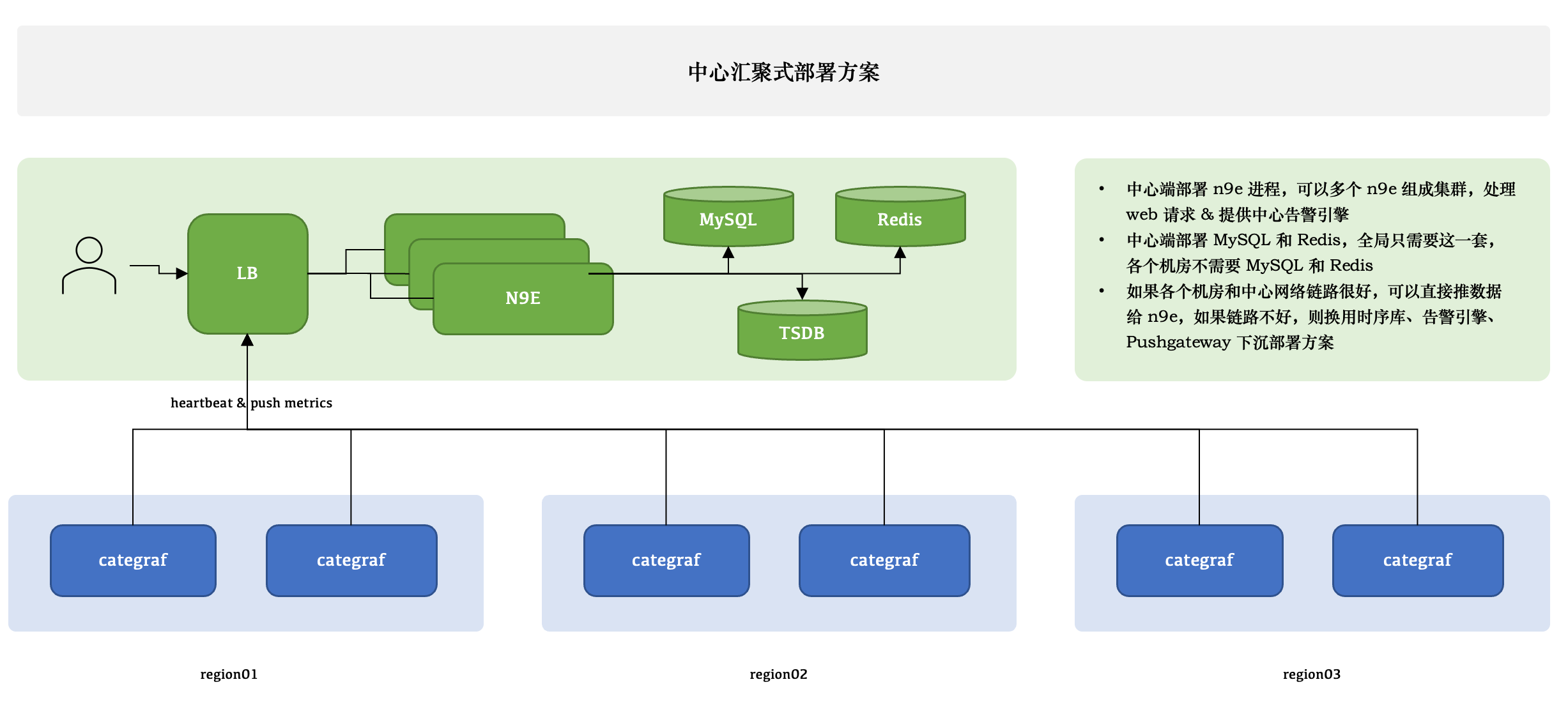
|
||||
|
||||
夜莺只有一个模块,就是 n9e,可以部署多个 n9e 实例组成集群,n9e 依赖 2 个存储,数据库、Redis,数据库可以使用 MySQL 或 Postgres,自己按需选用。
|
||||
|
||||
n9e 提供的是 HTTP 接口,前面负载均衡可以是 4 层的,也可以是 7 层的。一般就选用 Nginx 就可以了。
|
||||
|
||||
n9e 这个模块接收到数据之后,需要转发给后端的时序库,相关配置是:
|
||||
|
||||
```toml
|
||||
[Pushgw]
|
||||
LabelRewrite = true
|
||||
[[Pushgw.Writers]]
|
||||
Url = "http://127.0.0.1:9090/api/v1/write"
|
||||
```
|
||||
|
||||
> 注意:虽然数据源可以在页面配置了,但是上报转发链路,还是需要在配置文件指定。
|
||||
|
||||
所有机房的 agent( 比如 Categraf、Telegraf、 Grafana-agent、Datadog-agent ),都直接推数据给 n9e,这个架构最为简单,维护成本最低。当然,前提是要求机房之间网络链路比较好,一般有专线。如果网络链路不好,则要使用下面的部署方式了。
|
||||
|
||||
### 边缘下沉式混杂部署方案
|
||||
|
||||
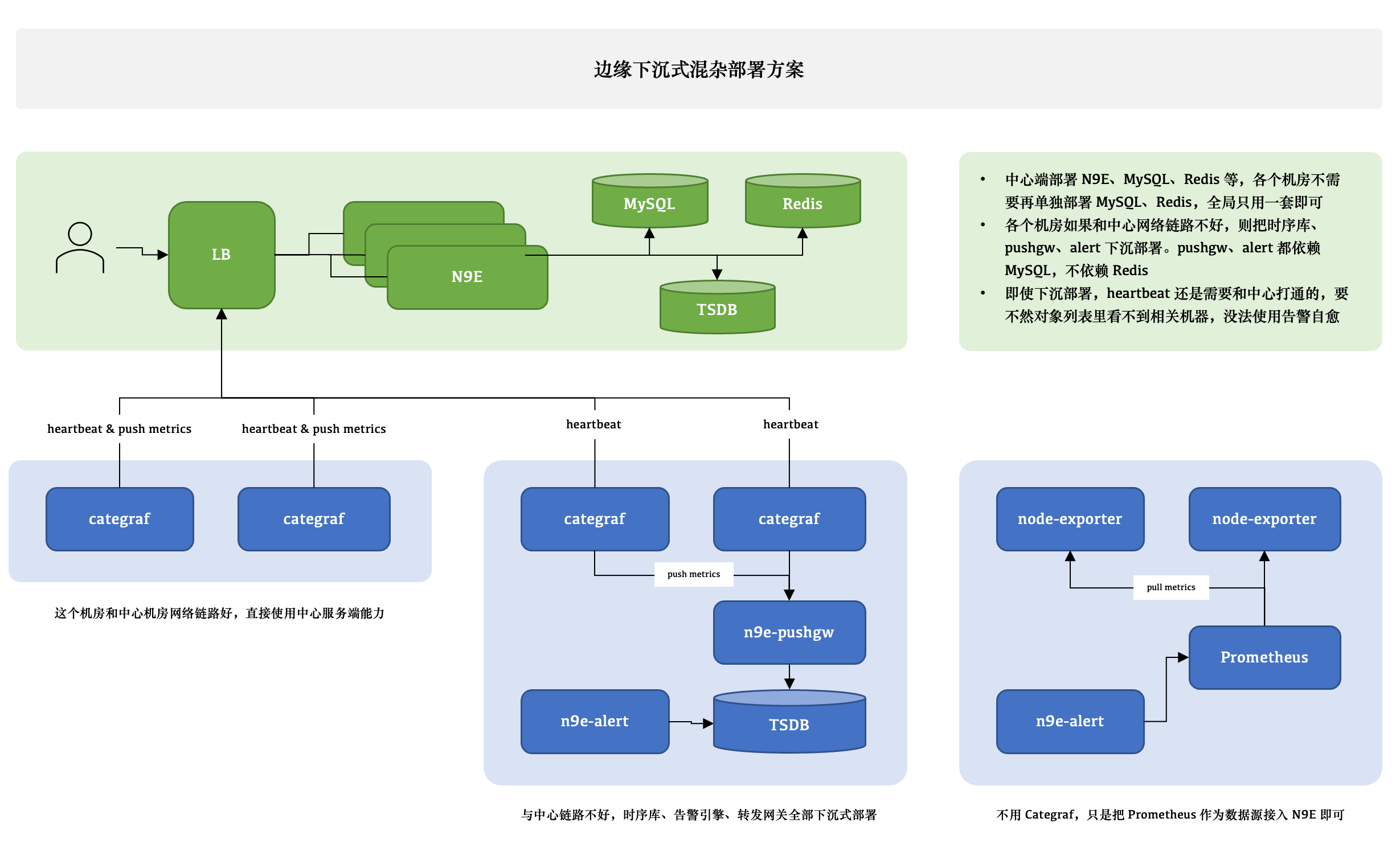
|
||||
|
||||
这个图尝试解释 3 种不同的情形,比如 A 机房和中心网络链路很好,Categraf 可以直接汇报数据给中心 n9e 模块,另一个机房网络链路不好,就需要把时序库下沉部署,时序库下沉了,对应的告警引擎和转发网关也都要跟随下沉,这样数据不会跨机房传输,比较稳定。但是心跳还是需要往中心心跳,要不然在对象列表里看不到机器的 CPU、内存使用率。还有的时候,可能是接入的一个已有的 Prometheus,数据采集没有走 Categraf,那此时只需要把 Prometheus 作为数据源接入夜莺即可,可以在夜莺里看图、配告警规则,但是就是在对象列表里看不到,也不能使用告警自愈的功能,问题也不大,核心功能都不受影响。
|
||||
|
||||
边缘机房,下沉部署时序库、告警引擎、转发网关的时候,要注意,告警引擎需要依赖数据库,因为要同步告警规则,转发网关也要依赖数据库,因为要注册对象到数据库里去,需要打通相关网络,告警引擎和转发网关都不用Redis,所以无需为 Redis 打通网络。
|
||||
|
||||
### VictoriaMetrics 集群架构
|
||||
<img src="doc/img/install-vm.png" width="600">
|
||||
|
||||
如果单机版本的时序数据库(比如 Prometheus) 性能有瓶颈或容灾较差,我们推荐使用 [VictoriaMetrics](https://github.com/VictoriaMetrics/VictoriaMetrics),VictoriaMetrics 架构较为简单,性能优异,易于部署和运维,架构图如上。VictoriaMetrics 更详尽的文档,还请参考其[官网](https://victoriametrics.com/)。
|
||||
|
||||
|
||||
## Community
|
||||
## 夜莺社区
|
||||
|
||||
开源项目要更有生命力,离不开开放的治理架构和源源不断的开发者和用户共同参与,我们致力于建立开放、中立的开源治理架构,吸纳更多来自企业、高校等各方面对云原生监控感兴趣、有热情的开发者,一起打造有活力的夜莺开源社区。关于《夜莺开源项目和社区治理架构(草案)》,请查阅 [COMMUNITY GOVERNANCE](./doc/community-governance.md).
|
||||
|
||||
**我们欢迎您以各种方式参与到夜莺开源项目和开源社区中来,工作包括不限于**:
|
||||
- 补充和完善文档 => [n9e.github.io](https://n9e.github.io/)
|
||||
- 分享您在使用夜莺监控过程中的最佳实践和经验心得 => [文章分享](https://n9e.github.io/docs/prologue/share/)
|
||||
- 分享您在使用夜莺监控过程中的最佳实践和经验心得 => [文章分享](https://flashcat.cloud/docs/content/flashcat-monitor/nightingale/share/)
|
||||
- 提交产品建议 =》 [github issue](https://github.com/ccfos/nightingale/issues/new?assignees=&labels=kind%2Ffeature&template=enhancement.md)
|
||||
- 提交代码,让夜莺监控更快、更稳、更好用 => [github pull request](https://github.com/didi/nightingale/pulls)
|
||||
|
||||
**尊重、认可和记录每一位贡献者的工作**是夜莺开源社区的第一指导原则,我们提倡**高效的提问**,这既是对开发者时间的尊重,也是对整个社区知识沉淀的贡献:
|
||||
- 提问之前请先查阅 [FAQ](https://www.gitlink.org.cn/ccfos/nightingale/wiki/faq)
|
||||
- 我们使用[GitHub Discussions](https://github.com/ccfos/nightingale/discussions)作为交流论坛,有问题可以到这里搜索、提问
|
||||
- 我们也推荐你加入微信群,和其他夜莺用户交流经验 (请先加好友:[picobyte](https://www.gitlink.org.cn/UlricQin/gist/tree/master/self.jpeg) 备注:夜莺加群+姓名+公司)
|
||||
- 我们使用[论坛](https://answer.flashcat.cloud/)进行交流,有问题可以到这里搜索、提问
|
||||
|
||||
|
||||
## Who is using Nightingale
|
||||
@@ -124,4 +144,4 @@ https://user-images.githubusercontent.com/792850/216888712-2565fcea-9df5-47bd-a4
|
||||
|
||||
## 加入交流群
|
||||
|
||||
<img src="doc/img/wecom.png" width="120">
|
||||
<img src="doc/img/wecom.png" width="120">
|
||||
@@ -4,8 +4,7 @@ FROM python:3-slim
|
||||
WORKDIR /app
|
||||
ADD n9e /app
|
||||
ADD http://download.flashcat.cloud/wait /wait
|
||||
RUN mkdir -p /app/pub && chmod +x /wait
|
||||
ADD pub /app/pub/
|
||||
RUN chmod +x /wait
|
||||
RUN chmod +x n9e
|
||||
|
||||
EXPOSE 17000
|
||||
|
||||
@@ -1,14 +1,12 @@
|
||||
FROM --platform=$BUILDPLATFORM python:3-slim
|
||||
FROM --platform=$TARGETPLATFORM python:3-slim
|
||||
|
||||
|
||||
WORKDIR /app
|
||||
ADD n9e /app
|
||||
ADD etc /app
|
||||
ADD inegrations /app
|
||||
ADD http://download.flashcat.cloud/wait /wait
|
||||
RUN mkdir -p /app/pub && chmod +x /wait
|
||||
ADD pub /app/pub/
|
||||
RUN chmod +x n9e
|
||||
ADD n9e /app/
|
||||
ADD etc /app/
|
||||
ADD integrations /app/integrations/
|
||||
ADD --chmod=755 https://github.com/ufoscout/docker-compose-wait/releases/download/2.11.0/wait_x86_64 /wait
|
||||
RUN chmod +x /wait
|
||||
|
||||
EXPOSE 17000
|
||||
|
||||
|
||||
13
docker/Dockerfile.goreleaser.arm64
Normal file
13
docker/Dockerfile.goreleaser.arm64
Normal file
@@ -0,0 +1,13 @@
|
||||
FROM flashcatcloud/toolbox:v0.0.1 as toolbox
|
||||
FROM --platform=$TARGETPLATFORM python:3-slim
|
||||
|
||||
|
||||
WORKDIR /app
|
||||
ADD n9e /app/
|
||||
ADD etc /app/
|
||||
ADD integrations /app/integrations/
|
||||
COPY --chmod=755 --from=toolbox /toolbox/wait_aarch64 /wait
|
||||
|
||||
EXPOSE 17000
|
||||
|
||||
CMD ["/app/n9e", "-h"]
|
||||
@@ -10,7 +10,6 @@ echo "tag: ${tag}"
|
||||
|
||||
rm -rf n9e pub
|
||||
cp ../n9e .
|
||||
cp -r ../pub .
|
||||
|
||||
docker build -t nightingale:${tag} .
|
||||
|
||||
|
||||
@@ -31,7 +31,7 @@ batch = 2000
|
||||
chan_size = 10000
|
||||
|
||||
[[writers]]
|
||||
url = "http://n9e:17000/prometheus/v1/write"
|
||||
url = "http://127.0.0.1:17000/prometheus/v1/write"
|
||||
|
||||
# Basic auth username
|
||||
basic_auth_user = ""
|
||||
@@ -54,7 +54,7 @@ run_mode = "release"
|
||||
enable = true
|
||||
|
||||
# report os version cpu.util mem.util metadata
|
||||
url = "http://n9e:17000/v1/n9e/heartbeat"
|
||||
url = "http://127.0.0.1:17000/v1/n9e/heartbeat"
|
||||
|
||||
# interval, unit: s
|
||||
interval = 10
|
||||
@@ -78,6 +78,6 @@ enable = true
|
||||
## ibex flush interval
|
||||
interval = "1000ms"
|
||||
## n9e ibex server rpc address
|
||||
servers = ["ibex:20090"]
|
||||
servers = ["127.0.0.1:20090"]
|
||||
## temp script dir
|
||||
meta_dir = "./meta"
|
||||
|
||||
@@ -1,9 +1,5 @@
|
||||
version: "3.7"
|
||||
|
||||
networks:
|
||||
nightingale:
|
||||
driver: bridge
|
||||
|
||||
services:
|
||||
mysql:
|
||||
# platform: linux/x86_64
|
||||
@@ -11,8 +7,6 @@ services:
|
||||
container_name: mysql
|
||||
hostname: mysql
|
||||
restart: always
|
||||
ports:
|
||||
- "3406:3306"
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
MYSQL_ROOT_PASSWORD: 1234
|
||||
@@ -20,20 +14,16 @@ services:
|
||||
- ./mysqldata:/var/lib/mysql/
|
||||
- ./initsql:/docker-entrypoint-initdb.d/
|
||||
- ./mysqletc/my.cnf:/etc/my.cnf
|
||||
networks:
|
||||
- nightingale
|
||||
network_mode: host
|
||||
|
||||
redis:
|
||||
image: "redis:6.2"
|
||||
container_name: redis
|
||||
hostname: redis
|
||||
restart: always
|
||||
ports:
|
||||
- "6379:6379"
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
networks:
|
||||
- nightingale
|
||||
network_mode: host
|
||||
|
||||
prometheus:
|
||||
image: prom/prometheus
|
||||
@@ -44,10 +34,7 @@ services:
|
||||
TZ: Asia/Shanghai
|
||||
volumes:
|
||||
- ./prometc:/etc/prometheus
|
||||
ports:
|
||||
- "9090:9090"
|
||||
networks:
|
||||
- nightingale
|
||||
network_mode: host
|
||||
command:
|
||||
- "--config.file=/etc/prometheus/prometheus.yml"
|
||||
- "--storage.tsdb.path=/prometheus"
|
||||
@@ -64,18 +51,12 @@ services:
|
||||
environment:
|
||||
GIN_MODE: release
|
||||
TZ: Asia/Shanghai
|
||||
WAIT_HOSTS: mysql:3306
|
||||
ports:
|
||||
- "10090:10090"
|
||||
- "20090:20090"
|
||||
WAIT_HOSTS: 127.0.0.1:3306
|
||||
volumes:
|
||||
- ./ibexetc:/app/etc
|
||||
networks:
|
||||
- nightingale
|
||||
network_mode: host
|
||||
depends_on:
|
||||
- mysql
|
||||
links:
|
||||
- mysql:mysql
|
||||
command: >
|
||||
sh -c "/wait && /app/ibex server"
|
||||
|
||||
@@ -87,24 +68,15 @@ services:
|
||||
environment:
|
||||
GIN_MODE: release
|
||||
TZ: Asia/Shanghai
|
||||
WAIT_HOSTS: mysql:3306, redis:6379
|
||||
WAIT_HOSTS: 127.0.0.1:3306, 127.0.0.1:6379
|
||||
volumes:
|
||||
- ./n9eetc:/app/etc
|
||||
- ./integrations:/app/integrations
|
||||
ports:
|
||||
- "17000:17000"
|
||||
networks:
|
||||
- nightingale
|
||||
- ../etc:/app/etc
|
||||
network_mode: host
|
||||
depends_on:
|
||||
- mysql
|
||||
- redis
|
||||
- prometheus
|
||||
- ibex
|
||||
links:
|
||||
- mysql:mysql
|
||||
- redis:redis
|
||||
- prometheus:prometheus
|
||||
- ibex:ibex
|
||||
command: >
|
||||
sh -c "/wait && /app/n9e"
|
||||
|
||||
@@ -122,13 +94,7 @@ services:
|
||||
- ./categraf/conf:/etc/categraf/conf
|
||||
- /:/hostfs
|
||||
- /var/run/docker.sock:/var/run/docker.sock
|
||||
# ports:
|
||||
# - "9100:9100/tcp"
|
||||
networks:
|
||||
- nightingale
|
||||
network_mode: host
|
||||
depends_on:
|
||||
- n9e
|
||||
- ibex
|
||||
links:
|
||||
- n9e:n9e
|
||||
- ibex:ibex
|
||||
- ibex
|
||||
83
docker/experience_pg_vm/categraf/conf/config.toml
Normal file
83
docker/experience_pg_vm/categraf/conf/config.toml
Normal file
@@ -0,0 +1,83 @@
|
||||
[global]
|
||||
# whether print configs
|
||||
print_configs = false
|
||||
|
||||
# add label(agent_hostname) to series
|
||||
# "" -> auto detect hostname
|
||||
# "xx" -> use specified string xx
|
||||
# "$hostname" -> auto detect hostname
|
||||
# "$ip" -> auto detect ip
|
||||
# "$hostname-$ip" -> auto detect hostname and ip to replace the vars
|
||||
hostname = "$HOSTNAME"
|
||||
|
||||
# will not add label(agent_hostname) if true
|
||||
omit_hostname = false
|
||||
|
||||
# s | ms
|
||||
precision = "ms"
|
||||
|
||||
# global collect interval
|
||||
interval = 15
|
||||
|
||||
[global.labels]
|
||||
source="categraf"
|
||||
# region = "shanghai"
|
||||
# env = "localhost"
|
||||
|
||||
[writer_opt]
|
||||
# default: 2000
|
||||
batch = 2000
|
||||
# channel(as queue) size
|
||||
chan_size = 10000
|
||||
|
||||
[[writers]]
|
||||
url = "http://n9e:17000/prometheus/v1/write"
|
||||
|
||||
# Basic auth username
|
||||
basic_auth_user = ""
|
||||
|
||||
# Basic auth password
|
||||
basic_auth_pass = ""
|
||||
|
||||
# timeout settings, unit: ms
|
||||
timeout = 5000
|
||||
dial_timeout = 2500
|
||||
max_idle_conns_per_host = 100
|
||||
|
||||
[http]
|
||||
enable = false
|
||||
address = ":9100"
|
||||
print_access = false
|
||||
run_mode = "release"
|
||||
|
||||
[heartbeat]
|
||||
enable = true
|
||||
|
||||
# report os version cpu.util mem.util metadata
|
||||
url = "http://n9e:17000/v1/n9e/heartbeat"
|
||||
|
||||
# interval, unit: s
|
||||
interval = 10
|
||||
|
||||
# Basic auth username
|
||||
basic_auth_user = ""
|
||||
|
||||
# Basic auth password
|
||||
basic_auth_pass = ""
|
||||
|
||||
## Optional headers
|
||||
# headers = ["X-From", "categraf", "X-Xyz", "abc"]
|
||||
|
||||
# timeout settings, unit: ms
|
||||
timeout = 5000
|
||||
dial_timeout = 2500
|
||||
max_idle_conns_per_host = 100
|
||||
|
||||
[ibex]
|
||||
enable = true
|
||||
## ibex flush interval
|
||||
interval = "1000ms"
|
||||
## n9e ibex server rpc address
|
||||
servers = ["ibex:20090"]
|
||||
## temp script dir
|
||||
meta_dir = "./meta"
|
||||
5
docker/experience_pg_vm/categraf/conf/input.cpu/cpu.toml
Normal file
5
docker/experience_pg_vm/categraf/conf/input.cpu/cpu.toml
Normal file
@@ -0,0 +1,5 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# # whether collect per cpu
|
||||
# collect_per_cpu = false
|
||||
11
docker/experience_pg_vm/categraf/conf/input.disk/disk.toml
Normal file
11
docker/experience_pg_vm/categraf/conf/input.disk/disk.toml
Normal file
@@ -0,0 +1,11 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# # By default stats will be gathered for all mount points.
|
||||
# # Set mount_points will restrict the stats to only the specified mount points.
|
||||
# mount_points = ["/"]
|
||||
|
||||
# Ignore mount points by filesystem type.
|
||||
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
|
||||
|
||||
ignore_mount_points = ["/boot"]
|
||||
@@ -0,0 +1,6 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# # By default, categraf will gather stats for all devices including disk partitions.
|
||||
# # Setting devices will restrict the stats to the specified devices.
|
||||
# devices = ["sda", "sdb", "vd*"]
|
||||
@@ -0,0 +1,63 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
[[instances]]
|
||||
# # append some labels for series
|
||||
# labels = { region="cloud", product="n9e" }
|
||||
|
||||
# # interval = global.interval * interval_times
|
||||
# interval_times = 1
|
||||
|
||||
## Docker Endpoint
|
||||
## To use TCP, set endpoint = "tcp://[ip]:[port]"
|
||||
## To use environment variables (ie, docker-machine), set endpoint = "ENV"
|
||||
endpoint = "unix:///var/run/docker.sock"
|
||||
|
||||
## Set to true to collect Swarm metrics(desired_replicas, running_replicas)
|
||||
gather_services = false
|
||||
gather_extend_memstats = false
|
||||
|
||||
container_id_label_enable = true
|
||||
container_id_label_short_style = true
|
||||
|
||||
## Containers to include and exclude. Globs accepted.
|
||||
## Note that an empty array for both will include all containers
|
||||
container_name_include = []
|
||||
container_name_exclude = []
|
||||
|
||||
## Container states to include and exclude. Globs accepted.
|
||||
## When empty only containers in the "running" state will be captured.
|
||||
## example: container_state_include = ["created", "restarting", "running", "removing", "paused", "exited", "dead"]
|
||||
## example: container_state_exclude = ["created", "restarting", "running", "removing", "paused", "exited", "dead"]
|
||||
# container_state_include = []
|
||||
# container_state_exclude = []
|
||||
|
||||
## Timeout for docker list, info, and stats commands
|
||||
timeout = "5s"
|
||||
|
||||
## Specifies for which classes a per-device metric should be issued
|
||||
## Possible values are 'cpu' (cpu0, cpu1, ...), 'blkio' (8:0, 8:1, ...) and 'network' (eth0, eth1, ...)
|
||||
## Please note that this setting has no effect if 'perdevice' is set to 'true'
|
||||
perdevice_include = []
|
||||
|
||||
## Specifies for which classes a total metric should be issued. Total is an aggregated of the 'perdevice' values.
|
||||
## Possible values are 'cpu', 'blkio' and 'network'
|
||||
## Total 'cpu' is reported directly by Docker daemon, and 'network' and 'blkio' totals are aggregated by this plugin.
|
||||
## Please note that this setting has no effect if 'total' is set to 'false'
|
||||
total_include = ["cpu", "blkio", "network"]
|
||||
|
||||
## Which environment variables should we use as a tag
|
||||
##tag_env = ["JAVA_HOME", "HEAP_SIZE"]
|
||||
|
||||
## docker labels to include and exclude as tags. Globs accepted.
|
||||
## Note that an empty array for both will include all labels as tags
|
||||
docker_label_include = []
|
||||
docker_label_exclude = ["annotation*", "io.kubernetes*", "*description*", "*maintainer*", "*hash", "*author*"]
|
||||
|
||||
## Optional TLS Config
|
||||
# use_tls = false
|
||||
# tls_ca = "/etc/telegraf/ca.pem"
|
||||
# tls_cert = "/etc/telegraf/cert.pem"
|
||||
# tls_key = "/etc/telegraf/key.pem"
|
||||
## Use TLS but skip chain & host verification
|
||||
# insecure_skip_verify = false
|
||||
@@ -0,0 +1,2 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
@@ -0,0 +1,124 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# file: /proc/vmstat
|
||||
[white_list]
|
||||
oom_kill = 1
|
||||
nr_free_pages = 0
|
||||
nr_alloc_batch = 0
|
||||
nr_inactive_anon = 0
|
||||
nr_active_anon = 0
|
||||
nr_inactive_file = 0
|
||||
nr_active_file = 0
|
||||
nr_unevictable = 0
|
||||
nr_mlock = 0
|
||||
nr_anon_pages = 0
|
||||
nr_mapped = 0
|
||||
nr_file_pages = 0
|
||||
nr_dirty = 0
|
||||
nr_writeback = 0
|
||||
nr_slab_reclaimable = 0
|
||||
nr_slab_unreclaimable = 0
|
||||
nr_page_table_pages = 0
|
||||
nr_kernel_stack = 0
|
||||
nr_unstable = 0
|
||||
nr_bounce = 0
|
||||
nr_vmscan_write = 0
|
||||
nr_vmscan_immediate_reclaim = 0
|
||||
nr_writeback_temp = 0
|
||||
nr_isolated_anon = 0
|
||||
nr_isolated_file = 0
|
||||
nr_shmem = 0
|
||||
nr_dirtied = 0
|
||||
nr_written = 0
|
||||
numa_hit = 0
|
||||
numa_miss = 0
|
||||
numa_foreign = 0
|
||||
numa_interleave = 0
|
||||
numa_local = 0
|
||||
numa_other = 0
|
||||
workingset_refault = 0
|
||||
workingset_activate = 0
|
||||
workingset_nodereclaim = 0
|
||||
nr_anon_transparent_hugepages = 0
|
||||
nr_free_cma = 0
|
||||
nr_dirty_threshold = 0
|
||||
nr_dirty_background_threshold = 0
|
||||
pgpgin = 0
|
||||
pgpgout = 0
|
||||
pswpin = 0
|
||||
pswpout = 0
|
||||
pgalloc_dma = 0
|
||||
pgalloc_dma32 = 0
|
||||
pgalloc_normal = 0
|
||||
pgalloc_movable = 0
|
||||
pgfree = 0
|
||||
pgactivate = 0
|
||||
pgdeactivate = 0
|
||||
pgfault = 0
|
||||
pgmajfault = 0
|
||||
pglazyfreed = 0
|
||||
pgrefill_dma = 0
|
||||
pgrefill_dma32 = 0
|
||||
pgrefill_normal = 0
|
||||
pgrefill_movable = 0
|
||||
pgsteal_kswapd_dma = 0
|
||||
pgsteal_kswapd_dma32 = 0
|
||||
pgsteal_kswapd_normal = 0
|
||||
pgsteal_kswapd_movable = 0
|
||||
pgsteal_direct_dma = 0
|
||||
pgsteal_direct_dma32 = 0
|
||||
pgsteal_direct_normal = 0
|
||||
pgsteal_direct_movable = 0
|
||||
pgscan_kswapd_dma = 0
|
||||
pgscan_kswapd_dma32 = 0
|
||||
pgscan_kswapd_normal = 0
|
||||
pgscan_kswapd_movable = 0
|
||||
pgscan_direct_dma = 0
|
||||
pgscan_direct_dma32 = 0
|
||||
pgscan_direct_normal = 0
|
||||
pgscan_direct_movable = 0
|
||||
pgscan_direct_throttle = 0
|
||||
zone_reclaim_failed = 0
|
||||
pginodesteal = 0
|
||||
slabs_scanned = 0
|
||||
kswapd_inodesteal = 0
|
||||
kswapd_low_wmark_hit_quickly = 0
|
||||
kswapd_high_wmark_hit_quickly = 0
|
||||
pageoutrun = 0
|
||||
allocstall = 0
|
||||
pgrotated = 0
|
||||
drop_pagecache = 0
|
||||
drop_slab = 0
|
||||
numa_pte_updates = 0
|
||||
numa_huge_pte_updates = 0
|
||||
numa_hint_faults = 0
|
||||
numa_hint_faults_local = 0
|
||||
numa_pages_migrated = 0
|
||||
pgmigrate_success = 0
|
||||
pgmigrate_fail = 0
|
||||
compact_migrate_scanned = 0
|
||||
compact_free_scanned = 0
|
||||
compact_isolated = 0
|
||||
compact_stall = 0
|
||||
compact_fail = 0
|
||||
compact_success = 0
|
||||
htlb_buddy_alloc_success = 0
|
||||
htlb_buddy_alloc_fail = 0
|
||||
unevictable_pgs_culled = 0
|
||||
unevictable_pgs_scanned = 0
|
||||
unevictable_pgs_rescued = 0
|
||||
unevictable_pgs_mlocked = 0
|
||||
unevictable_pgs_munlocked = 0
|
||||
unevictable_pgs_cleared = 0
|
||||
unevictable_pgs_stranded = 0
|
||||
thp_fault_alloc = 0
|
||||
thp_fault_fallback = 0
|
||||
thp_collapse_alloc = 0
|
||||
thp_collapse_alloc_failed = 0
|
||||
thp_split = 0
|
||||
thp_zero_page_alloc = 0
|
||||
thp_zero_page_alloc_failed = 0
|
||||
balloon_inflate = 0
|
||||
balloon_deflate = 0
|
||||
balloon_migrate = 0
|
||||
@@ -0,0 +1,2 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
5
docker/experience_pg_vm/categraf/conf/input.mem/mem.toml
Normal file
5
docker/experience_pg_vm/categraf/conf/input.mem/mem.toml
Normal file
@@ -0,0 +1,5 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# # whether collect platform specified metrics
|
||||
collect_platform_fields = true
|
||||
8
docker/experience_pg_vm/categraf/conf/input.net/net.toml
Normal file
8
docker/experience_pg_vm/categraf/conf/input.net/net.toml
Normal file
@@ -0,0 +1,8 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# # whether collect protocol stats on Linux
|
||||
# collect_protocol_stats = false
|
||||
|
||||
# # setting interfaces will tell categraf to gather these explicit interfaces
|
||||
# interfaces = ["eth0"]
|
||||
@@ -0,0 +1,2 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
@@ -0,0 +1,8 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# # force use ps command to gather
|
||||
# force_ps = false
|
||||
|
||||
# # force use /proc to gather
|
||||
# force_proc = false
|
||||
@@ -0,0 +1,5 @@
|
||||
# # collect interval
|
||||
# interval = 15
|
||||
|
||||
# # whether collect metric: system_n_users
|
||||
# collect_user_number = false
|
||||
10
docker/experience_pg_vm/categraf/conf/prometheus.toml
Normal file
10
docker/experience_pg_vm/categraf/conf/prometheus.toml
Normal file
@@ -0,0 +1,10 @@
|
||||
[prometheus]
|
||||
enable=true
|
||||
scrape_config_file="/etc/prometheus/prometheus.yml"
|
||||
## log level, debug warn info error
|
||||
log_level="info"
|
||||
## wal file storage path ,default ./data-agent
|
||||
# wal_storage_path="/path/to/storage"
|
||||
## wal reserve time duration, default value is 2 hour
|
||||
# wal_min_duration=2
|
||||
|
||||
129
docker/experience_pg_vm/docker-compose.yaml
Normal file
129
docker/experience_pg_vm/docker-compose.yaml
Normal file
@@ -0,0 +1,129 @@
|
||||
version: "3.7"
|
||||
|
||||
networks:
|
||||
nightingale:
|
||||
driver: bridge
|
||||
|
||||
services:
|
||||
postgres:
|
||||
# platform: linux/x86_64
|
||||
image: "postgres:12-alpine"
|
||||
container_name: postgres
|
||||
hostname: postgres
|
||||
restart: always
|
||||
ports:
|
||||
- "5432:5432"
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
POSTGRES_USER: root
|
||||
POSTGRES_PASSWORD: 1234
|
||||
POSTGRES_DB: n9e_v6
|
||||
PGDATA: /var/lib/postgresql/data/pgdata
|
||||
volumes:
|
||||
- ./pgdata:/var/lib/postgresql/data
|
||||
- ./initsql_for_postgres:/docker-entrypoint-initdb.d/
|
||||
networks:
|
||||
- nightingale
|
||||
|
||||
redis:
|
||||
image: "redis:7.0-alpine"
|
||||
container_name: redis
|
||||
hostname: redis
|
||||
restart: always
|
||||
ports:
|
||||
- "6379:6379"
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
networks:
|
||||
- nightingale
|
||||
|
||||
victoriametrics:
|
||||
image: victoriametrics/victoria-metrics:v1.79.12
|
||||
container_name: victoriametrics
|
||||
hostname: victoriametrics
|
||||
restart: always
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
ports:
|
||||
- "8428:8428"
|
||||
networks:
|
||||
- nightingale
|
||||
command:
|
||||
- "--loggerTimezone=Asia/Shanghai"
|
||||
|
||||
ibex:
|
||||
image: ulric2019/ibex:0.3
|
||||
container_name: ibex
|
||||
hostname: ibex
|
||||
restart: always
|
||||
environment:
|
||||
GIN_MODE: release
|
||||
TZ: Asia/Shanghai
|
||||
WAIT_HOSTS: postgres:5432
|
||||
ports:
|
||||
- "10090:10090"
|
||||
- "20090:20090"
|
||||
volumes:
|
||||
- ./ibexetc_pg:/app/etc
|
||||
networks:
|
||||
- nightingale
|
||||
depends_on:
|
||||
- postgres
|
||||
links:
|
||||
- postgres:postgres
|
||||
command: >
|
||||
sh -c "/wait && /app/ibex server"
|
||||
|
||||
n9e:
|
||||
image: flashcatcloud/nightingale:latest
|
||||
container_name: n9e
|
||||
hostname: n9e
|
||||
restart: always
|
||||
environment:
|
||||
GIN_MODE: release
|
||||
TZ: Asia/Shanghai
|
||||
WAIT_HOSTS: postgres:5432, redis:6379
|
||||
volumes:
|
||||
- ./n9eetc_pg:/app/etc
|
||||
ports:
|
||||
- "17000:17000"
|
||||
networks:
|
||||
- nightingale
|
||||
depends_on:
|
||||
- postgres
|
||||
- redis
|
||||
- victoriametrics
|
||||
- ibex
|
||||
links:
|
||||
- postgres:postgres
|
||||
- redis:redis
|
||||
- victoriametrics:victoriametrics
|
||||
- ibex:ibex
|
||||
command: >
|
||||
sh -c "/wait && /app/n9e"
|
||||
|
||||
categraf:
|
||||
image: "flashcatcloud/categraf:latest"
|
||||
container_name: "categraf"
|
||||
hostname: "categraf01"
|
||||
restart: always
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
HOST_PROC: /hostfs/proc
|
||||
HOST_SYS: /hostfs/sys
|
||||
HOST_MOUNT_PREFIX: /hostfs
|
||||
volumes:
|
||||
- ./categraf/conf:/etc/categraf/conf
|
||||
- /:/hostfs
|
||||
- /var/run/docker.sock:/var/run/docker.sock
|
||||
- ./prometc_vm:/etc/prometheus
|
||||
# ports:
|
||||
# - "9100:9100/tcp"
|
||||
networks:
|
||||
- nightingale
|
||||
depends_on:
|
||||
- n9e
|
||||
- ibex
|
||||
links:
|
||||
- n9e:n9e
|
||||
- ibex:ibex
|
||||
97
docker/experience_pg_vm/ibexetc_pg/server.conf
Normal file
97
docker/experience_pg_vm/ibexetc_pg/server.conf
Normal file
@@ -0,0 +1,97 @@
|
||||
# debug, release
|
||||
RunMode = "release"
|
||||
|
||||
[Log]
|
||||
# log write dir
|
||||
Dir = "logs-server"
|
||||
# log level: DEBUG INFO WARNING ERROR
|
||||
Level = "DEBUG"
|
||||
# stdout, stderr, file
|
||||
Output = "stdout"
|
||||
# # rotate by time
|
||||
# KeepHours: 4
|
||||
# # rotate by size
|
||||
# RotateNum = 3
|
||||
# # unit: MB
|
||||
# RotateSize = 256
|
||||
|
||||
[HTTP]
|
||||
Enable = true
|
||||
# http listening address
|
||||
Host = "0.0.0.0"
|
||||
# http listening port
|
||||
Port = 10090
|
||||
# https cert file path
|
||||
CertFile = ""
|
||||
# https key file path
|
||||
KeyFile = ""
|
||||
# whether print access log
|
||||
PrintAccessLog = true
|
||||
# whether enable pprof
|
||||
PProf = false
|
||||
# http graceful shutdown timeout, unit: s
|
||||
ShutdownTimeout = 30
|
||||
# max content length: 64M
|
||||
MaxContentLength = 67108864
|
||||
# http server read timeout, unit: s
|
||||
ReadTimeout = 20
|
||||
# http server write timeout, unit: s
|
||||
WriteTimeout = 40
|
||||
# http server idle timeout, unit: s
|
||||
IdleTimeout = 120
|
||||
|
||||
[BasicAuth]
|
||||
# using when call apis
|
||||
ibex = "ibex"
|
||||
|
||||
[RPC]
|
||||
Listen = "0.0.0.0:20090"
|
||||
|
||||
[Heartbeat]
|
||||
# auto detect if blank
|
||||
IP = ""
|
||||
# unit: ms
|
||||
Interval = 1000
|
||||
|
||||
[Output]
|
||||
# database | remote
|
||||
ComeFrom = "database"
|
||||
AgtdPort = 2090
|
||||
|
||||
[Gorm]
|
||||
# enable debug mode or not
|
||||
Debug = false
|
||||
# mysql postgres
|
||||
DBType = "postgres"
|
||||
# unit: s
|
||||
MaxLifetime = 7200
|
||||
# max open connections
|
||||
MaxOpenConns = 150
|
||||
# max idle connections
|
||||
MaxIdleConns = 50
|
||||
# table prefix
|
||||
TablePrefix = ""
|
||||
|
||||
[MySQL]
|
||||
# mysql address host:port
|
||||
Address = "mysql:3306"
|
||||
# mysql username
|
||||
User = "root"
|
||||
# mysql password
|
||||
Password = "1234"
|
||||
# database name
|
||||
DBName = "ibex"
|
||||
# connection params
|
||||
Parameters = "charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true"
|
||||
|
||||
[Postgres]
|
||||
# pg address host:port
|
||||
Address = "postgres:5432"
|
||||
# pg user
|
||||
User = "root"
|
||||
# pg password
|
||||
Password = "1234"
|
||||
# database name
|
||||
DBName = "n9e_v6"
|
||||
# ssl mode
|
||||
SSLMode = "disable"
|
||||
@@ -0,0 +1,735 @@
|
||||
CREATE TABLE users (
|
||||
id bigserial,
|
||||
username varchar(64) not null ,
|
||||
nickname varchar(64) not null ,
|
||||
password varchar(128) not null default '',
|
||||
phone varchar(16) not null default '',
|
||||
email varchar(64) not null default '',
|
||||
portrait varchar(255) not null default '' ,
|
||||
roles varchar(255) not null ,
|
||||
contacts varchar(1024) ,
|
||||
maintainer smallint not null default 0,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (username)
|
||||
) ;
|
||||
COMMENT ON COLUMN users.username IS 'login name, cannot rename';
|
||||
COMMENT ON COLUMN users.nickname IS 'display name, chinese name';
|
||||
COMMENT ON COLUMN users.portrait IS 'portrait image url';
|
||||
COMMENT ON COLUMN users.roles IS 'Admin | Standard | Guest, split by space';
|
||||
COMMENT ON COLUMN users.contacts IS 'json e.g. {wecom:xx, dingtalk_robot_token:yy}';
|
||||
|
||||
insert into users(id, username, nickname, password, roles, create_at, create_by, update_at, update_by) values(1, 'root', '超管', 'root.2020', 'Admin', date_part('epoch',current_timestamp)::int, 'system', date_part('epoch',current_timestamp)::int, 'system');
|
||||
|
||||
CREATE TABLE user_group (
|
||||
id bigserial,
|
||||
name varchar(128) not null default '',
|
||||
note varchar(255) not null default '',
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX user_group_create_by_idx ON user_group (create_by);
|
||||
CREATE INDEX user_group_update_at_idx ON user_group (update_at);
|
||||
|
||||
insert into user_group(id, name, create_at, create_by, update_at, update_by) values(1, 'demo-root-group', date_part('epoch',current_timestamp)::int, 'root', date_part('epoch',current_timestamp)::int, 'root');
|
||||
|
||||
CREATE TABLE user_group_member (
|
||||
id bigserial,
|
||||
group_id bigint not null,
|
||||
user_id bigint not null,
|
||||
PRIMARY KEY(id)
|
||||
) ;
|
||||
CREATE INDEX user_group_member_group_id_idx ON user_group_member (group_id);
|
||||
CREATE INDEX user_group_member_user_id_idx ON user_group_member (user_id);
|
||||
|
||||
insert into user_group_member(group_id, user_id) values(1, 1);
|
||||
|
||||
CREATE TABLE configs (
|
||||
id bigserial,
|
||||
ckey varchar(191) not null,
|
||||
cval varchar(4096) not null default '',
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (ckey)
|
||||
) ;
|
||||
|
||||
CREATE TABLE role (
|
||||
id bigserial,
|
||||
name varchar(191) not null default '',
|
||||
note varchar(255) not null default '',
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (name)
|
||||
) ;
|
||||
|
||||
insert into role(name, note) values('Admin', 'Administrator role');
|
||||
insert into role(name, note) values('Standard', 'Ordinary user role');
|
||||
insert into role(name, note) values('Guest', 'Readonly user role');
|
||||
|
||||
CREATE TABLE role_operation(
|
||||
id bigserial,
|
||||
role_name varchar(128) not null,
|
||||
operation varchar(191) not null,
|
||||
PRIMARY KEY(id)
|
||||
) ;
|
||||
CREATE INDEX role_operation_role_name_idx ON role_operation (role_name);
|
||||
CREATE INDEX role_operation_operation_idx ON role_operation (operation);
|
||||
|
||||
|
||||
-- Admin is special, who has no concrete operation but can do anything.
|
||||
insert into role_operation(role_name, operation) values('Guest', '/metric/explorer');
|
||||
insert into role_operation(role_name, operation) values('Guest', '/object/explorer');
|
||||
insert into role_operation(role_name, operation) values('Guest', '/log/explorer');
|
||||
insert into role_operation(role_name, operation) values('Guest', '/trace/explorer');
|
||||
insert into role_operation(role_name, operation) values('Guest', '/help/version');
|
||||
insert into role_operation(role_name, operation) values('Guest', '/help/contact');
|
||||
|
||||
insert into role_operation(role_name, operation) values('Standard', '/metric/explorer');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/object/explorer');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/log/explorer');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/trace/explorer');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/help/version');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/help/contact');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-rules-built-in');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/dashboards-built-in');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/trace/dependencies');
|
||||
|
||||
insert into role_operation(role_name, operation) values('Standard', '/users');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/user-groups');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/user-groups/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/user-groups/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/user-groups/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/busi-groups');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/busi-groups/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/busi-groups/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/busi-groups/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/targets');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/targets/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/targets/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/targets/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/dashboards');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/dashboards/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/dashboards/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/dashboards/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-rules');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-rules/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-rules/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-rules/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-mutes');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-mutes/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-mutes/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-subscribes');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-subscribes/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-subscribes/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-subscribes/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-cur-events');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-cur-events/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/alert-his-events');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/job-tpls');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/job-tpls/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/job-tpls/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/job-tpls/del');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/job-tasks');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/job-tasks/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/job-tasks/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/recording-rules');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/recording-rules/add');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/recording-rules/put');
|
||||
insert into role_operation(role_name, operation) values('Standard', '/recording-rules/del');
|
||||
|
||||
-- for alert_rule | collect_rule | mute | dashboard grouping
|
||||
CREATE TABLE busi_group (
|
||||
id bigserial,
|
||||
name varchar(191) not null,
|
||||
label_enable smallint not null default 0,
|
||||
label_value varchar(191) not null default '' ,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (name)
|
||||
) ;
|
||||
COMMENT ON COLUMN busi_group.label_value IS 'if label_enable: label_value can not be blank';
|
||||
|
||||
insert into busi_group(id, name, create_at, create_by, update_at, update_by) values(1, 'Default Busi Group', date_part('epoch',current_timestamp)::int, 'root', date_part('epoch',current_timestamp)::int, 'root');
|
||||
|
||||
CREATE TABLE busi_group_member (
|
||||
id bigserial,
|
||||
busi_group_id bigint not null ,
|
||||
user_group_id bigint not null ,
|
||||
perm_flag char(2) not null ,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX busi_group_member_busi_group_id_idx ON busi_group_member (busi_group_id);
|
||||
CREATE INDEX busi_group_member_user_group_id_idx ON busi_group_member (user_group_id);
|
||||
COMMENT ON COLUMN busi_group_member.busi_group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN busi_group_member.user_group_id IS 'user group id';
|
||||
COMMENT ON COLUMN busi_group_member.perm_flag IS 'ro | rw';
|
||||
|
||||
|
||||
insert into busi_group_member(busi_group_id, user_group_id, perm_flag) values(1, 1, 'rw');
|
||||
|
||||
-- for dashboard new version
|
||||
CREATE TABLE board (
|
||||
id bigserial,
|
||||
group_id bigint not null default 0 ,
|
||||
name varchar(191) not null,
|
||||
ident varchar(200) not null default '',
|
||||
tags varchar(255) not null ,
|
||||
public smallint not null default 0 ,
|
||||
built_in smallint not null default 0 ,
|
||||
hide smallint not null default 0 ,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (group_id, name)
|
||||
) ;
|
||||
CREATE INDEX board_ident_idx ON board (ident);
|
||||
COMMENT ON COLUMN board.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN board.tags IS 'split by space';
|
||||
COMMENT ON COLUMN board.public IS '0:false 1:true';
|
||||
COMMENT ON COLUMN board.built_in IS '0:false 1:true';
|
||||
COMMENT ON COLUMN board.hide IS '0:false 1:true';
|
||||
|
||||
|
||||
-- for dashboard new version
|
||||
CREATE TABLE board_payload (
|
||||
id bigint not null ,
|
||||
payload text not null,
|
||||
UNIQUE (id)
|
||||
) ;
|
||||
COMMENT ON COLUMN board_payload.id IS 'dashboard id';
|
||||
|
||||
-- deprecated
|
||||
CREATE TABLE dashboard (
|
||||
id bigserial,
|
||||
group_id bigint not null default 0 ,
|
||||
name varchar(191) not null,
|
||||
tags varchar(255) not null ,
|
||||
configs varchar(8192) ,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (group_id, name)
|
||||
) ;
|
||||
COMMENT ON COLUMN dashboard.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN dashboard.tags IS 'split by space';
|
||||
COMMENT ON COLUMN dashboard.configs IS 'dashboard variables';
|
||||
|
||||
-- deprecated
|
||||
-- auto create the first subclass 'Default chart group' of dashboard
|
||||
CREATE TABLE chart_group (
|
||||
id bigserial,
|
||||
dashboard_id bigint not null,
|
||||
name varchar(255) not null,
|
||||
weight int not null default 0,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX chart_group_dashboard_id_idx ON chart_group (dashboard_id);
|
||||
|
||||
-- deprecated
|
||||
CREATE TABLE chart (
|
||||
id bigserial,
|
||||
group_id bigint not null ,
|
||||
configs text,
|
||||
weight int not null default 0,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX chart_group_id_idx ON chart (group_id);
|
||||
COMMENT ON COLUMN chart.group_id IS 'chart group id';
|
||||
|
||||
|
||||
CREATE TABLE chart_share (
|
||||
id bigserial,
|
||||
cluster varchar(128) not null,
|
||||
datasource_id bigint not null default 0,
|
||||
configs text,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
primary key (id)
|
||||
) ;
|
||||
CREATE INDEX chart_share_create_at_idx ON chart_share (create_at);
|
||||
|
||||
|
||||
CREATE TABLE alert_rule (
|
||||
id bigserial,
|
||||
group_id bigint not null default 0 ,
|
||||
cate varchar(128) not null,
|
||||
datasource_ids varchar(255) not null default '' ,
|
||||
cluster varchar(128) not null,
|
||||
name varchar(255) not null,
|
||||
note varchar(1024) not null default '',
|
||||
prod varchar(255) not null default '',
|
||||
algorithm varchar(255) not null default '',
|
||||
algo_params varchar(255),
|
||||
delay int not null default 0,
|
||||
severity smallint not null ,
|
||||
disabled smallint not null ,
|
||||
prom_for_duration int not null ,
|
||||
rule_config text not null ,
|
||||
prom_ql text not null ,
|
||||
prom_eval_interval int not null ,
|
||||
enable_stime varchar(255) not null default '00:00',
|
||||
enable_etime varchar(255) not null default '23:59',
|
||||
enable_days_of_week varchar(255) not null default '' ,
|
||||
enable_in_bg smallint not null default 0 ,
|
||||
notify_recovered smallint not null ,
|
||||
notify_channels varchar(255) not null default '' ,
|
||||
notify_groups varchar(255) not null default '' ,
|
||||
notify_repeat_step int not null default 0 ,
|
||||
notify_max_number int not null default 0 ,
|
||||
recover_duration int not null default 0 ,
|
||||
callbacks varchar(255) not null default '' ,
|
||||
runbook_url varchar(255),
|
||||
append_tags varchar(255) not null default '' ,
|
||||
annotations text not null ,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX alert_rule_group_id_idx ON alert_rule (group_id);
|
||||
CREATE INDEX alert_rule_update_at_idx ON alert_rule (update_at);
|
||||
COMMENT ON COLUMN alert_rule.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN alert_rule.datasource_ids IS 'datasource ids';
|
||||
COMMENT ON COLUMN alert_rule.severity IS '1:Emergency 2:Warning 3:Notice';
|
||||
COMMENT ON COLUMN alert_rule.disabled IS '0:enabled 1:disabled';
|
||||
COMMENT ON COLUMN alert_rule.prom_for_duration IS 'prometheus for, unit:s';
|
||||
COMMENT ON COLUMN alert_rule.rule_config IS 'rule_config';
|
||||
COMMENT ON COLUMN alert_rule.prom_ql IS 'promql';
|
||||
COMMENT ON COLUMN alert_rule.prom_eval_interval IS 'evaluate interval';
|
||||
COMMENT ON COLUMN alert_rule.enable_stime IS '00:00';
|
||||
COMMENT ON COLUMN alert_rule.enable_etime IS '23:59';
|
||||
COMMENT ON COLUMN alert_rule.enable_days_of_week IS 'split by space: 0 1 2 3 4 5 6';
|
||||
COMMENT ON COLUMN alert_rule.enable_in_bg IS '1: only this bg 0: global';
|
||||
COMMENT ON COLUMN alert_rule.notify_recovered IS 'whether notify when recovery';
|
||||
COMMENT ON COLUMN alert_rule.notify_channels IS 'split by space: sms voice email dingtalk wecom';
|
||||
COMMENT ON COLUMN alert_rule.notify_groups IS 'split by space: 233 43';
|
||||
COMMENT ON COLUMN alert_rule.notify_repeat_step IS 'unit: min';
|
||||
COMMENT ON COLUMN alert_rule.recover_duration IS 'unit: s';
|
||||
COMMENT ON COLUMN alert_rule.callbacks IS 'split by space: http://a.com/api/x http://a.com/api/y';
|
||||
COMMENT ON COLUMN alert_rule.append_tags IS 'split by space: service=n9e mod=api';
|
||||
COMMENT ON COLUMN alert_rule.annotations IS 'annotations';
|
||||
|
||||
|
||||
CREATE TABLE alert_mute (
|
||||
id bigserial,
|
||||
group_id bigint not null default 0 ,
|
||||
prod varchar(255) not null default '',
|
||||
note varchar(1024) not null default '',
|
||||
cate varchar(128) not null,
|
||||
cluster varchar(128) not null,
|
||||
datasource_ids varchar(255) not null default '' ,
|
||||
tags jsonb NOT NULL ,
|
||||
cause varchar(255) not null default '',
|
||||
btime bigint not null default 0 ,
|
||||
etime bigint not null default 0 ,
|
||||
disabled smallint not null default 0 ,
|
||||
mute_time_type smallint not null default 0,
|
||||
periodic_mutes varchar(4096) not null default '',
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX alert_mute_group_id_idx ON alert_mute (group_id);
|
||||
CREATE INDEX alert_mute_update_at_idx ON alert_mute (update_at);
|
||||
COMMENT ON COLUMN alert_mute.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN alert_mute.datasource_ids IS 'datasource ids';
|
||||
COMMENT ON COLUMN alert_mute.tags IS 'json,map,tagkey->regexp|value';
|
||||
COMMENT ON COLUMN alert_mute.btime IS 'begin time';
|
||||
COMMENT ON COLUMN alert_mute.etime IS 'end time';
|
||||
COMMENT ON COLUMN alert_mute.disabled IS '0:enabled 1:disabled';
|
||||
|
||||
|
||||
CREATE TABLE alert_subscribe (
|
||||
id bigserial,
|
||||
name varchar(255) not null default '',
|
||||
disabled smallint not null default 0 ,
|
||||
group_id bigint not null default 0 ,
|
||||
prod varchar(255) not null default '',
|
||||
cate varchar(128) not null,
|
||||
datasource_ids varchar(255) not null default '' ,
|
||||
cluster varchar(128) not null,
|
||||
rule_id bigint not null default 0,
|
||||
tags varchar(4096) not null default '' ,
|
||||
redefine_severity smallint default 0 ,
|
||||
new_severity smallint not null ,
|
||||
redefine_channels smallint default 0 ,
|
||||
new_channels varchar(255) not null default '' ,
|
||||
user_group_ids varchar(250) not null ,
|
||||
webhooks text not null,
|
||||
redefine_webhooks smallint default 0,
|
||||
for_duration bigint not null default 0,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX alert_subscribe_group_id_idx ON alert_subscribe (group_id);
|
||||
CREATE INDEX alert_subscribe_update_at_idx ON alert_subscribe (update_at);
|
||||
COMMENT ON COLUMN alert_subscribe.disabled IS '0:enabled 1:disabled';
|
||||
COMMENT ON COLUMN alert_subscribe.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN alert_subscribe.datasource_ids IS 'datasource ids';
|
||||
COMMENT ON COLUMN alert_subscribe.tags IS 'json,map,tagkey->regexp|value';
|
||||
COMMENT ON COLUMN alert_subscribe.redefine_severity IS 'is redefine severity?';
|
||||
COMMENT ON COLUMN alert_subscribe.new_severity IS '0:Emergency 1:Warning 2:Notice';
|
||||
COMMENT ON COLUMN alert_subscribe.redefine_channels IS 'is redefine channels?';
|
||||
COMMENT ON COLUMN alert_subscribe.new_channels IS 'split by space: sms voice email dingtalk wecom';
|
||||
COMMENT ON COLUMN alert_subscribe.user_group_ids IS 'split by space 1 34 5, notify cc to user_group_ids';
|
||||
|
||||
|
||||
CREATE TABLE target (
|
||||
id bigserial,
|
||||
group_id bigint not null default 0 ,
|
||||
ident varchar(191) not null ,
|
||||
note varchar(255) not null default '' ,
|
||||
tags varchar(512) not null default '' ,
|
||||
update_at bigint not null default 0,
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (ident)
|
||||
) ;
|
||||
CREATE INDEX target_group_id_idx ON target (group_id);
|
||||
COMMENT ON COLUMN target.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN target.ident IS 'target id';
|
||||
COMMENT ON COLUMN target.note IS 'append to alert event as field';
|
||||
COMMENT ON COLUMN target.tags IS 'append to series data as tags, split by space, append external space at suffix';
|
||||
|
||||
-- case1: target_idents; case2: target_tags
|
||||
-- CREATE TABLE collect_rule (
|
||||
-- id bigserial,
|
||||
-- group_id bigint not null default 0 comment 'busi group id',
|
||||
-- cluster varchar(128) not null,
|
||||
-- target_idents varchar(512) not null default '' comment 'ident list, split by space',
|
||||
-- target_tags varchar(512) not null default '' comment 'filter targets by tags, split by space',
|
||||
-- name varchar(191) not null default '',
|
||||
-- note varchar(255) not null default '',
|
||||
-- step int not null,
|
||||
-- type varchar(64) not null comment 'e.g. port proc log plugin',
|
||||
-- data text not null,
|
||||
-- append_tags varchar(255) not null default '' comment 'split by space: e.g. mod=n9e dept=cloud',
|
||||
-- create_at bigint not null default 0,
|
||||
-- create_by varchar(64) not null default '',
|
||||
-- update_at bigint not null default 0,
|
||||
-- update_by varchar(64) not null default '',
|
||||
-- PRIMARY KEY (id),
|
||||
-- KEY (group_id, type, name)
|
||||
-- ) ;
|
||||
|
||||
CREATE TABLE metric_view (
|
||||
id bigserial,
|
||||
name varchar(191) not null default '',
|
||||
cate smallint not null ,
|
||||
configs varchar(8192) not null default '',
|
||||
create_at bigint not null default 0,
|
||||
create_by bigint not null default 0,
|
||||
update_at bigint not null default 0,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX metric_view_create_by_idx ON metric_view (create_by);
|
||||
COMMENT ON COLUMN metric_view.cate IS '0: preset 1: custom';
|
||||
COMMENT ON COLUMN metric_view.create_by IS 'user id';
|
||||
|
||||
|
||||
insert into metric_view(name, cate, configs) values('Host View', 0, '{"filters":[{"oper":"=","label":"__name__","value":"cpu_usage_idle"}],"dynamicLabels":[],"dimensionLabels":[{"label":"ident","value":""}]}');
|
||||
|
||||
CREATE TABLE recording_rule (
|
||||
id bigserial,
|
||||
group_id bigint not null default '0',
|
||||
datasource_ids varchar(255) not null default '',
|
||||
cluster varchar(128) not null,
|
||||
name varchar(255) not null ,
|
||||
note varchar(255) not null ,
|
||||
disabled smallint not null default 0 ,
|
||||
prom_ql varchar(8192) not null ,
|
||||
prom_eval_interval int not null ,
|
||||
append_tags varchar(255) default '' ,
|
||||
create_at bigint default '0',
|
||||
create_by varchar(64) default '',
|
||||
update_at bigint default '0',
|
||||
update_by varchar(64) default '',
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX recording_rule_group_id_idx ON recording_rule (group_id);
|
||||
CREATE INDEX recording_rule_update_at_idx ON recording_rule (update_at);
|
||||
COMMENT ON COLUMN recording_rule.group_id IS 'group_id';
|
||||
COMMENT ON COLUMN recording_rule.datasource_ids IS 'datasource ids';
|
||||
COMMENT ON COLUMN recording_rule.name IS 'new metric name';
|
||||
COMMENT ON COLUMN recording_rule.note IS 'rule note';
|
||||
COMMENT ON COLUMN recording_rule.disabled IS '0:enabled 1:disabled';
|
||||
COMMENT ON COLUMN recording_rule.prom_ql IS 'promql';
|
||||
COMMENT ON COLUMN recording_rule.prom_eval_interval IS 'evaluate interval';
|
||||
COMMENT ON COLUMN recording_rule.append_tags IS 'split by space: service=n9e mod=api';
|
||||
|
||||
|
||||
CREATE TABLE alert_aggr_view (
|
||||
id bigserial,
|
||||
name varchar(191) not null default '',
|
||||
rule varchar(2048) not null default '',
|
||||
cate smallint not null ,
|
||||
create_at bigint not null default 0,
|
||||
create_by bigint not null default 0,
|
||||
update_at bigint not null default 0,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX alert_aggr_view_create_by_idx ON alert_aggr_view (create_by);
|
||||
COMMENT ON COLUMN alert_aggr_view.cate IS '0: preset 1: custom';
|
||||
COMMENT ON COLUMN alert_aggr_view.create_by IS 'user id';
|
||||
|
||||
|
||||
insert into alert_aggr_view(name, rule, cate) values('By BusiGroup, Severity', 'field:group_name::field:severity', 0);
|
||||
insert into alert_aggr_view(name, rule, cate) values('By RuleName', 'field:rule_name', 0);
|
||||
|
||||
CREATE TABLE alert_cur_event (
|
||||
id bigint not null ,
|
||||
cate varchar(128) not null,
|
||||
datasource_id bigint not null default 0 ,
|
||||
cluster varchar(128) not null,
|
||||
group_id bigint not null ,
|
||||
group_name varchar(255) not null default '' ,
|
||||
hash varchar(64) not null ,
|
||||
rule_id bigint not null,
|
||||
rule_name varchar(255) not null,
|
||||
rule_note varchar(2048) not null ,
|
||||
rule_prod varchar(255) not null default '',
|
||||
rule_algo varchar(255) not null default '',
|
||||
severity smallint not null ,
|
||||
prom_for_duration int not null ,
|
||||
prom_ql varchar(8192) not null ,
|
||||
prom_eval_interval int not null ,
|
||||
callbacks varchar(255) not null default '' ,
|
||||
runbook_url varchar(255),
|
||||
notify_recovered smallint not null ,
|
||||
notify_channels varchar(255) not null default '' ,
|
||||
notify_groups varchar(255) not null default '' ,
|
||||
notify_repeat_next bigint not null default 0 ,
|
||||
notify_cur_number int not null default 0 ,
|
||||
target_ident varchar(191) not null default '' ,
|
||||
target_note varchar(191) not null default '' ,
|
||||
first_trigger_time bigint,
|
||||
trigger_time bigint not null,
|
||||
trigger_value varchar(255) not null,
|
||||
annotations text not null ,
|
||||
rule_config text not null ,
|
||||
tags varchar(1024) not null default '' ,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX alert_cur_event_hash_idx ON alert_cur_event (hash);
|
||||
CREATE INDEX alert_cur_event_rule_id_idx ON alert_cur_event (rule_id);
|
||||
CREATE INDEX alert_cur_event_tg_idx ON alert_cur_event (trigger_time, group_id);
|
||||
CREATE INDEX alert_cur_event_nrn_idx ON alert_cur_event (notify_repeat_next);
|
||||
COMMENT ON COLUMN alert_cur_event.id IS 'use alert_his_event.id';
|
||||
COMMENT ON COLUMN alert_cur_event.datasource_id IS 'datasource id';
|
||||
COMMENT ON COLUMN alert_cur_event.group_id IS 'busi group id of rule';
|
||||
COMMENT ON COLUMN alert_cur_event.group_name IS 'busi group name';
|
||||
COMMENT ON COLUMN alert_cur_event.hash IS 'rule_id + vector_pk';
|
||||
COMMENT ON COLUMN alert_cur_event.rule_note IS 'alert rule note';
|
||||
COMMENT ON COLUMN alert_cur_event.severity IS '1:Emergency 2:Warning 3:Notice';
|
||||
COMMENT ON COLUMN alert_cur_event.prom_for_duration IS 'prometheus for, unit:s';
|
||||
COMMENT ON COLUMN alert_cur_event.prom_ql IS 'promql';
|
||||
COMMENT ON COLUMN alert_cur_event.prom_eval_interval IS 'evaluate interval';
|
||||
COMMENT ON COLUMN alert_cur_event.callbacks IS 'split by space: http://a.com/api/x http://a.com/api/y';
|
||||
COMMENT ON COLUMN alert_cur_event.notify_recovered IS 'whether notify when recovery';
|
||||
COMMENT ON COLUMN alert_cur_event.notify_channels IS 'split by space: sms voice email dingtalk wecom';
|
||||
COMMENT ON COLUMN alert_cur_event.notify_groups IS 'split by space: 233 43';
|
||||
COMMENT ON COLUMN alert_cur_event.notify_repeat_next IS 'next timestamp to notify, get repeat settings from rule';
|
||||
COMMENT ON COLUMN alert_cur_event.target_ident IS 'target ident, also in tags';
|
||||
COMMENT ON COLUMN alert_cur_event.target_note IS 'target note';
|
||||
COMMENT ON COLUMN alert_cur_event.annotations IS 'annotations';
|
||||
COMMENT ON COLUMN alert_cur_event.rule_config IS 'rule_config';
|
||||
COMMENT ON COLUMN alert_cur_event.tags IS 'merge data_tags rule_tags, split by ,,';
|
||||
|
||||
|
||||
CREATE TABLE alert_his_event (
|
||||
id bigserial,
|
||||
is_recovered smallint not null,
|
||||
cate varchar(128) not null,
|
||||
datasource_id bigint not null default 0 ,
|
||||
cluster varchar(128) not null,
|
||||
group_id bigint not null ,
|
||||
group_name varchar(255) not null default '' ,
|
||||
hash varchar(64) not null ,
|
||||
rule_id bigint not null,
|
||||
rule_name varchar(255) not null,
|
||||
rule_note varchar(2048) not null default 'alert rule note',
|
||||
rule_prod varchar(255) not null default '',
|
||||
rule_algo varchar(255) not null default '',
|
||||
severity smallint not null ,
|
||||
prom_for_duration int not null ,
|
||||
prom_ql varchar(8192) not null ,
|
||||
prom_eval_interval int not null ,
|
||||
callbacks varchar(255) not null default '' ,
|
||||
runbook_url varchar(255),
|
||||
notify_recovered smallint not null ,
|
||||
notify_channels varchar(255) not null default '' ,
|
||||
notify_groups varchar(255) not null default '' ,
|
||||
notify_cur_number int not null default 0 ,
|
||||
target_ident varchar(191) not null default '' ,
|
||||
target_note varchar(191) not null default '' ,
|
||||
first_trigger_time bigint,
|
||||
trigger_time bigint not null,
|
||||
trigger_value varchar(255) not null,
|
||||
recover_time bigint not null default 0,
|
||||
last_eval_time bigint not null default 0 ,
|
||||
tags varchar(1024) not null default '' ,
|
||||
annotations text not null ,
|
||||
rule_config text not null ,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX alert_his_event_hash_idx ON alert_his_event (hash);
|
||||
CREATE INDEX alert_his_event_rule_id_idx ON alert_his_event (rule_id);
|
||||
CREATE INDEX alert_his_event_tg_idx ON alert_his_event (trigger_time, group_id);
|
||||
COMMENT ON COLUMN alert_his_event.group_id IS 'busi group id of rule';
|
||||
COMMENT ON COLUMN alert_his_event.datasource_id IS 'datasource id';
|
||||
COMMENT ON COLUMN alert_his_event.group_name IS 'busi group name';
|
||||
COMMENT ON COLUMN alert_his_event.hash IS 'rule_id + vector_pk';
|
||||
COMMENT ON COLUMN alert_his_event.rule_note IS 'alert rule note';
|
||||
COMMENT ON COLUMN alert_his_event.severity IS '0:Emergency 1:Warning 2:Notice';
|
||||
COMMENT ON COLUMN alert_his_event.prom_for_duration IS 'prometheus for, unit:s';
|
||||
COMMENT ON COLUMN alert_his_event.prom_ql IS 'promql';
|
||||
COMMENT ON COLUMN alert_his_event.prom_eval_interval IS 'evaluate interval';
|
||||
COMMENT ON COLUMN alert_his_event.callbacks IS 'split by space: http://a.com/api/x http://a.com/api/y';
|
||||
COMMENT ON COLUMN alert_his_event.notify_recovered IS 'whether notify when recovery';
|
||||
COMMENT ON COLUMN alert_his_event.notify_channels IS 'split by space: sms voice email dingtalk wecom';
|
||||
COMMENT ON COLUMN alert_his_event.notify_groups IS 'split by space: 233 43';
|
||||
COMMENT ON COLUMN alert_his_event.target_ident IS 'target ident, also in tags';
|
||||
COMMENT ON COLUMN alert_his_event.target_note IS 'target note';
|
||||
COMMENT ON COLUMN alert_his_event.last_eval_time IS 'for time filter';
|
||||
COMMENT ON COLUMN alert_his_event.tags IS 'merge data_tags rule_tags, split by ,,';
|
||||
COMMENT ON COLUMN alert_his_event.annotations IS 'annotations';
|
||||
COMMENT ON COLUMN alert_his_event.rule_config IS 'rule_config';
|
||||
|
||||
CREATE TABLE task_tpl
|
||||
(
|
||||
id serial,
|
||||
group_id int not null ,
|
||||
title varchar(255) not null default '',
|
||||
account varchar(64) not null,
|
||||
batch int not null default 0,
|
||||
tolerance int not null default 0,
|
||||
timeout int not null default 0,
|
||||
pause varchar(255) not null default '',
|
||||
script text not null,
|
||||
args varchar(512) not null default '',
|
||||
tags varchar(255) not null default '' ,
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
update_at bigint not null default 0,
|
||||
update_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX task_tpl_group_id_idx ON task_tpl (group_id);
|
||||
COMMENT ON COLUMN task_tpl.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN task_tpl.tags IS 'split by space';
|
||||
|
||||
|
||||
CREATE TABLE task_tpl_host
|
||||
(
|
||||
ii serial,
|
||||
id int not null ,
|
||||
host varchar(128) not null ,
|
||||
PRIMARY KEY (ii)
|
||||
) ;
|
||||
CREATE INDEX task_tpl_host_id_host_idx ON task_tpl_host (id, host);
|
||||
COMMENT ON COLUMN task_tpl_host.id IS 'task tpl id';
|
||||
COMMENT ON COLUMN task_tpl_host.host IS 'ip or hostname';
|
||||
|
||||
|
||||
CREATE TABLE task_record
|
||||
(
|
||||
id bigint not null ,
|
||||
event_id bigint not null default 0,
|
||||
group_id bigint not null ,
|
||||
ibex_address varchar(128) not null,
|
||||
ibex_auth_user varchar(128) not null default '',
|
||||
ibex_auth_pass varchar(128) not null default '',
|
||||
title varchar(255) not null default '',
|
||||
account varchar(64) not null,
|
||||
batch int not null default 0,
|
||||
tolerance int not null default 0,
|
||||
timeout int not null default 0,
|
||||
pause varchar(255) not null default '',
|
||||
script text not null,
|
||||
args varchar(512) not null default '',
|
||||
create_at bigint not null default 0,
|
||||
create_by varchar(64) not null default '',
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
CREATE INDEX task_record_cg_idx ON task_record (create_at, group_id);
|
||||
CREATE INDEX task_record_create_by_idx ON task_record (create_by);
|
||||
CREATE INDEX task_record_event_id_idx ON task_record (event_id);
|
||||
COMMENT ON COLUMN task_record.id IS 'ibex task id';
|
||||
COMMENT ON COLUMN task_record.group_id IS 'busi group id';
|
||||
COMMENT ON COLUMN task_record.event_id IS 'event id';
|
||||
|
||||
CREATE TABLE alerting_engines
|
||||
(
|
||||
id serial,
|
||||
instance varchar(128) not null default '' ,
|
||||
datasource_id bigint not null default 0 ,
|
||||
engine_cluster varchar(128) not null default '' ,
|
||||
clock bigint not null,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
COMMENT ON COLUMN alerting_engines.instance IS 'instance identification, e.g. 10.9.0.9:9090';
|
||||
COMMENT ON COLUMN alerting_engines.datasource_id IS 'datasource id';
|
||||
COMMENT ON COLUMN alerting_engines.engine_cluster IS 'target reader cluster';
|
||||
|
||||
|
||||
CREATE TABLE datasource
|
||||
(
|
||||
id serial,
|
||||
name varchar(191) not null default '',
|
||||
description varchar(255) not null default '',
|
||||
category varchar(255) not null default '',
|
||||
plugin_id int not null default 0,
|
||||
plugin_type varchar(255) not null default '',
|
||||
plugin_type_name varchar(255) not null default '',
|
||||
cluster_name varchar(255) not null default '',
|
||||
settings text not null,
|
||||
status varchar(255) not null default '',
|
||||
http varchar(4096) not null default '',
|
||||
auth varchar(8192) not null default '',
|
||||
created_at bigint not null default 0,
|
||||
created_by varchar(64) not null default '',
|
||||
updated_at bigint not null default 0,
|
||||
updated_by varchar(64) not null default '',
|
||||
UNIQUE (name),
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
|
||||
CREATE TABLE builtin_cate (
|
||||
id bigserial,
|
||||
name varchar(191) not null,
|
||||
user_id bigint not null default 0,
|
||||
PRIMARY KEY (id)
|
||||
) ;
|
||||
|
||||
CREATE TABLE notify_tpl (
|
||||
id bigserial,
|
||||
channel varchar(32) not null,
|
||||
name varchar(255) not null,
|
||||
content text not null,
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (channel)
|
||||
) ;
|
||||
|
||||
CREATE TABLE sso_config (
|
||||
id bigserial,
|
||||
name varchar(191) not null,
|
||||
content text not null,
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE (name)
|
||||
) ;
|
||||
1254
docker/experience_pg_vm/initsql_for_postgres/b-ibex-for-Postgres.sql
Normal file
1254
docker/experience_pg_vm/initsql_for_postgres/b-ibex-for-Postgres.sql
Normal file
File diff suppressed because it is too large
Load Diff
@@ -78,12 +78,11 @@ HeaderUserNameKey = "X-User-Name"
|
||||
DefaultRoles = ["Standard"]
|
||||
|
||||
[DB]
|
||||
# postgres: host=%s port=%s user=%s dbname=%s password=%s sslmode=%s
|
||||
DSN="root:1234@tcp(mysql:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true"
|
||||
DSN="host=postgres port=5432 user=root dbname=n9e_v6 password=1234 sslmode=disable"
|
||||
# enable debug mode or not
|
||||
Debug = false
|
||||
# mysql postgres
|
||||
DBType = "mysql"
|
||||
DBType = "postgres"
|
||||
# unit: s
|
||||
MaxLifetime = 7200
|
||||
# max open connections
|
||||
@@ -141,4 +140,4 @@ Timeout = 3000
|
||||
LabelRewrite = true
|
||||
|
||||
[[Pushgw.Writers]]
|
||||
Url = "http://prometheus:9090/api/v1/write"
|
||||
Url = "http://victoriametrics:8428/api/v1/write"
|
||||
25
docker/experience_pg_vm/prometc_vm/prometheus.yml
Normal file
25
docker/experience_pg_vm/prometc_vm/prometheus.yml
Normal file
@@ -0,0 +1,25 @@
|
||||
# my global config
|
||||
global:
|
||||
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
|
||||
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
|
||||
# scrape_timeout is set to the global default (10s).
|
||||
|
||||
# A scrape configuration containing exactly one endpoint to scrape:
|
||||
# Here it's Prometheus itself.
|
||||
scrape_configs:
|
||||
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
|
||||
- job_name: 'victoriametrics'
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
static_configs:
|
||||
- targets: ['victoriametrics:8428']
|
||||
|
||||
- job_name: 'n9e'
|
||||
# static_configs:
|
||||
# - targets: ['n9e:17000']
|
||||
file_sd_configs:
|
||||
- files:
|
||||
- targets.json
|
||||
|
||||
remote_write:
|
||||
- url: 'http://n9e:17000/prometheus/v1/write'
|
||||
7
docker/experience_pg_vm/prometc_vm/targets.json
Normal file
7
docker/experience_pg_vm/prometc_vm/targets.json
Normal file
@@ -0,0 +1,7 @@
|
||||
[
|
||||
{
|
||||
"targets": [
|
||||
"n9e:17000"
|
||||
]
|
||||
}
|
||||
]
|
||||
@@ -74,7 +74,7 @@ TablePrefix = ""
|
||||
|
||||
[MySQL]
|
||||
# mysql address host:port
|
||||
Address = "mysql:3306"
|
||||
Address = "127.0.0.1:3306"
|
||||
# mysql username
|
||||
User = "root"
|
||||
# mysql password
|
||||
@@ -86,7 +86,7 @@ Parameters = "charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true
|
||||
|
||||
[Postgres]
|
||||
# pg address host:port
|
||||
Address = "postgres:5432"
|
||||
Address = "127.0.0.1:5432"
|
||||
# pg user
|
||||
User = "root"
|
||||
# pg password
|
||||
|
||||
@@ -167,7 +167,7 @@ CREATE TABLE `busi_group_member` (
|
||||
KEY (`user_group_id`)
|
||||
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
insert into busi_group_member(busi_group_id, user_group_id, perm_flag) values(1, 1, "rw");
|
||||
insert into busi_group_member(busi_group_id, user_group_id, perm_flag) values(1, 1, 'rw');
|
||||
|
||||
-- for dashboard new version
|
||||
CREATE TABLE `board` (
|
||||
@@ -234,7 +234,7 @@ CREATE TABLE `chart` (
|
||||
CREATE TABLE `chart_share` (
|
||||
`id` bigint unsigned not null auto_increment,
|
||||
`cluster` varchar(128) not null,
|
||||
`dashboard_id` bigint unsigned not null,
|
||||
`datasource_id` bigint unsigned not null default 0,
|
||||
`configs` text,
|
||||
`create_at` bigint not null default 0,
|
||||
`create_by` varchar(64) not null default '',
|
||||
@@ -334,7 +334,7 @@ CREATE TABLE `alert_subscribe` (
|
||||
KEY (`update_at`),
|
||||
KEY (`group_id`)
|
||||
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
|
||||
CREATE TABLE `target` (
|
||||
`id` bigint unsigned not null auto_increment,
|
||||
`group_id` bigint not null default 0 comment 'busi group id',
|
||||
@@ -383,11 +383,11 @@ CREATE TABLE `metric_view` (
|
||||
) ENGINE=InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
insert into metric_view(name, cate, configs) values('Host View', 0, '{"filters":[{"oper":"=","label":"__name__","value":"cpu_usage_idle"}],"dynamicLabels":[],"dimensionLabels":[{"label":"ident","value":""}]}');
|
||||
|
||||
|
||||
CREATE TABLE `recording_rule` (
|
||||
`id` bigint unsigned not null auto_increment,
|
||||
`group_id` bigint not null default '0' comment 'group_id',
|
||||
`datasource_id` bigint not null default 0 comment 'datasource id',
|
||||
`datasource_ids` varchar(255) not null default '' comment 'datasource ids',
|
||||
`cluster` varchar(128) not null,
|
||||
`name` varchar(255) not null comment 'new metric name',
|
||||
`note` varchar(255) not null comment 'rule note',
|
||||
@@ -531,6 +531,7 @@ CREATE TABLE `task_tpl_host`
|
||||
CREATE TABLE `task_record`
|
||||
(
|
||||
`id` bigint unsigned not null comment 'ibex task id',
|
||||
`event_id` bigint not null comment 'event id' default 0,
|
||||
`group_id` bigint not null comment 'busi group id',
|
||||
`ibex_address` varchar(128) not null,
|
||||
`ibex_auth_user` varchar(128) not null default '',
|
||||
@@ -547,7 +548,8 @@ CREATE TABLE `task_record`
|
||||
`create_by` varchar(64) not null default '',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY (`create_at`, `group_id`),
|
||||
KEY (`create_by`)
|
||||
KEY (`create_by`),
|
||||
KEY (`event_id`)
|
||||
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
CREATE TABLE `alerting_engines`
|
||||
@@ -555,12 +557,11 @@ CREATE TABLE `alerting_engines`
|
||||
`id` int unsigned NOT NULL AUTO_INCREMENT,
|
||||
`instance` varchar(128) not null default '' comment 'instance identification, e.g. 10.9.0.9:9090',
|
||||
`datasource_id` bigint not null default 0 comment 'datasource id',
|
||||
`cluster` varchar(128) not null default '' comment 'n9e-alert cluster',
|
||||
`engine_cluster` varchar(128) not null default '' comment 'n9e-alert cluster',
|
||||
`clock` bigint not null,
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
|
||||
CREATE TABLE `datasource`
|
||||
(
|
||||
`id` int unsigned NOT NULL AUTO_INCREMENT,
|
||||
@@ -581,15 +582,15 @@ CREATE TABLE `datasource`
|
||||
`updated_by` varchar(64) not null default '',
|
||||
UNIQUE KEY (`name`),
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
CREATE TABLE `builtin_cate` (
|
||||
`id` bigint unsigned not null auto_increment,
|
||||
`name` varchar(191) not null,
|
||||
`user_id` bigint not null default 0,
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
|
||||
|
||||
|
||||
CREATE TABLE `notify_tpl` (
|
||||
`id` bigint unsigned not null auto_increment,
|
||||
`channel` varchar(32) not null,
|
||||
|
||||
@@ -1,392 +0,0 @@
|
||||
[
|
||||
{
|
||||
"name": "Elastic Cluster Red status",
|
||||
"note": "",
|
||||
"severity": 1,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 0,
|
||||
"prom_ql": " elasticsearch_cluster_health_status{color=\"red\"} == 1",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchClusterRed"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elastic Cluster Yellow status",
|
||||
"note": "",
|
||||
"severity": 2,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 0,
|
||||
"prom_ql": "elasticsearch_cluster_health_status{color=\"yellow\"} == 1",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchClusterYellow"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch disk out of space of the instance",
|
||||
"note": "",
|
||||
"severity": 1,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 120,
|
||||
"prom_ql": "elasticsearch_filesystem_data_available_bytes / elasticsearch_filesystem_data_size_bytes * 100 < 10",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchDiskOutOfSpace"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch disk space low of the instance",
|
||||
"note": "",
|
||||
"severity": 2,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 120,
|
||||
"prom_ql": "elasticsearch_filesystem_data_available_bytes / elasticsearch_filesystem_data_size_bytes * 100 < 20",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchDiskSpaceLow"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch Heap Usage Too High of the instance",
|
||||
"note": "",
|
||||
"severity": 1,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 120,
|
||||
"prom_ql": "(elasticsearch_jvm_memory_used_bytes{area=\"heap\"} / elasticsearch_jvm_memory_max_bytes{area=\"heap\"}) * 100 > 90",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchHeapUsageTooHigh"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch Heap Usage warning of the instance",
|
||||
"note": "",
|
||||
"severity": 2,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 120,
|
||||
"prom_ql": "(elasticsearch_jvm_memory_used_bytes{area=\"heap\"} / elasticsearch_jvm_memory_max_bytes{area=\"heap\"}) * 100 > 80",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchHeapUsageWarning"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch initializing shards of the instance",
|
||||
"note": "",
|
||||
"severity": 2,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 900,
|
||||
"prom_ql": "elasticsearch_cluster_health_initializing_shards > 0",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchInitializingShards"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch no new documents of the instance",
|
||||
"note": "",
|
||||
"severity": 2,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 300,
|
||||
"prom_ql": "rate(elasticsearch_indices_docs{es_data_node=\"true\"}[5m]) == 0",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchNoNewDocuments"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch pending tasks of the instance",
|
||||
"note": "",
|
||||
"severity": 2,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 900,
|
||||
"prom_ql": "elasticsearch_cluster_health_number_of_pending_tasks > 0",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchPendingTasks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch relocation shards of the instance",
|
||||
"note": "",
|
||||
"severity": 1,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 900,
|
||||
"prom_ql": "elasticsearch_cluster_health_relocating_shards > 0",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchRelocationShards"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch unassigned shards of the instance",
|
||||
"note": "",
|
||||
"severity": 1,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 0,
|
||||
"prom_ql": "elasticsearch_cluster_health_unassigned_shards > 0",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchUnassignedShards"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch Unhealthy Data Nodes",
|
||||
"note": "",
|
||||
"severity": 1,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 0,
|
||||
"prom_ql": "elasticsearch_cluster_health_number_of_data_nodes < number_of_data_nodes",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchHealthyDataNodes"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Elasticsearch Unhealthy Nodes",
|
||||
"note": "",
|
||||
"severity": 1,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 0,
|
||||
"prom_ql": " elasticsearch_cluster_health_number_of_nodes < number_of_nodes",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": [
|
||||
"alertname=ElasticsearchHealthyNodes"
|
||||
]
|
||||
}
|
||||
]
|
||||
File diff suppressed because it is too large
Load Diff
{kind=link}
@@ -1,28 +0,0 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" width="32px" height="32px" viewBox="0 0 32 32" version="1.1">
|
||||
<!-- Generator: Sketch 54.1 (76490) - https://sketchapp.com -->
|
||||
<title>icon / product-logo / 32x32px / elasticsearch / color</title>
|
||||
<desc>Created with Sketch.</desc>
|
||||
<defs>
|
||||
<polygon id="path-1" points="0.6438 0.0005 27.479 0.0005 27.479 9.0005 0.6438 9.0005"/>
|
||||
<polygon id="path-3" points="0.6437 0.0004 27.479 0.0004 27.479 9 0.6437 9"/>
|
||||
</defs>
|
||||
<g id="icon-/-product-logo-/-32x32px-/-elasticsearch-/-color" stroke="none" stroke-width="1" fill="none" fill-rule="evenodd">
|
||||
<g id="Group-9" transform="translate(1.000000, 0.000000)">
|
||||
<path d="M0,16.0004 C0,17.3844 0.194,18.7194 0.524,20.0004 L20,20.0004 C22.209,20.0004 24,18.2094 24,16.0004 C24,13.7904 22.209,12.0004 20,12.0004 L0.524,12.0004 C0.194,13.2804 0,14.6164 0,16.0004" id="Fill-1" fill="#343741"/>
|
||||
<g id="Group-5" transform="translate(1.000000, 0.000000)">
|
||||
<mask id="mask-2" fill="white">
|
||||
<use xlink:href="#path-1"/>
|
||||
</mask>
|
||||
<g id="Clip-4"/>
|
||||
<path d="M25.9238,7.6615 C26.4828,7.1465 27.0028,6.5935 27.4798,6.0005 C24.5468,2.3455 20.0498,0.0005 14.9998,0.0005 C8.6788,0.0005 3.2388,3.6775 0.6438,9.0005 L22.5108,9.0005 C23.7768,9.0005 24.9938,8.5195 25.9238,7.6615" id="Fill-3" fill="#FEC514" mask="url(#mask-2)"/>
|
||||
</g>
|
||||
<g id="Group-8" transform="translate(1.000000, 23.000000)">
|
||||
<mask id="mask-4" fill="white">
|
||||
<use xlink:href="#path-3"/>
|
||||
</mask>
|
||||
<g id="Clip-7"/>
|
||||
<path d="M22.5107,0.0004 L0.6437,0.0004 C3.2397,5.3224 8.6787,9.0004 14.9997,9.0004 C20.0497,9.0004 24.5467,6.6544 27.4797,3.0004 C27.0027,2.4064 26.4827,1.8534 25.9237,1.3384 C24.9937,0.4794 23.7767,0.0004 22.5107,0.0004" id="Fill-6" fill="#00BFB3" mask="url(#mask-4)"/>
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 2.0 KiB |
@@ -1,30 +0,0 @@
|
||||
[
|
||||
{
|
||||
"name": "http detect failed",
|
||||
"note": "",
|
||||
"severity": 2,
|
||||
"disabled": 0,
|
||||
"prom_for_duration": 60,
|
||||
"prom_ql": "http_response_result_code != 0",
|
||||
"prom_eval_interval": 15,
|
||||
"enable_stime": "00:00",
|
||||
"enable_etime": "23:59",
|
||||
"enable_days_of_week": [
|
||||
"1",
|
||||
"2",
|
||||
"3",
|
||||
"4",
|
||||
"5",
|
||||
"6",
|
||||
"0"
|
||||
],
|
||||
"enable_in_bg": 0,
|
||||
"notify_recovered": 1,
|
||||
"notify_channels": [],
|
||||
"notify_repeat_step": 60,
|
||||
"recover_duration": 0,
|
||||
"callbacks": [],
|
||||
"runbook_url": "",
|
||||
"append_tags": []
|
||||
}
|
||||
]
|
||||
@@ -1,112 +0,0 @@
|
||||
{
|
||||
"name": "http detect",
|
||||
"tags": "",
|
||||
"ident": "",
|
||||
"configs": {
|
||||
"version": "2.0.0",
|
||||
"panels": [
|
||||
{
|
||||
"id": "0cd7c8aa-456c-4522-97ef-0b1710e7af8a",
|
||||
"type": "row",
|
||||
"name": "Default chart group",
|
||||
"layout": {
|
||||
"h": 1,
|
||||
"w": 24,
|
||||
"x": 0,
|
||||
"y": 0,
|
||||
"i": "0cd7c8aa-456c-4522-97ef-0b1710e7af8a"
|
||||
},
|
||||
"collapsed": true
|
||||
},
|
||||
{
|
||||
"targets": [
|
||||
{
|
||||
"refId": "A",
|
||||
"expr": "max(http_response_result_code) by (target)",
|
||||
"legend": "UP?"
|
||||
},
|
||||
{
|
||||
"expr": "max(http_response_response_code) by (target)",
|
||||
"refId": "B",
|
||||
"legend": "status code"
|
||||
},
|
||||
{
|
||||
"expr": "max(http_response_response_time) by (target)",
|
||||
"refId": "C",
|
||||
"legend": "latency(s)"
|
||||
},
|
||||
{
|
||||
"expr": "max(http_response_cert_expire_timestamp) by (target) - time()",
|
||||
"refId": "D",
|
||||
"legend": "cert expire"
|
||||
}
|
||||
],
|
||||
"name": "URL Details",
|
||||
"custom": {
|
||||
"showHeader": true,
|
||||
"calc": "lastNotNull",
|
||||
"displayMode": "labelValuesToRows",
|
||||
"aggrDimension": "target"
|
||||
},
|
||||
"options": {
|
||||
"valueMappings": [],
|
||||
"standardOptions": {}
|
||||
},
|
||||
"overrides": [
|
||||
{
|
||||
"properties": {
|
||||
"valueMappings": [
|
||||
{
|
||||
"type": "special",
|
||||
"match": {
|
||||
"special": 0
|
||||
},
|
||||
"result": {
|
||||
"text": "UP",
|
||||
"color": "#417505"
|
||||
}
|
||||
},
|
||||
{
|
||||
"type": "range",
|
||||
"match": {
|
||||
"special": 1,
|
||||
"from": 1
|
||||
},
|
||||
"result": {
|
||||
"text": "DOWN",
|
||||
"color": "#e90f0f"
|
||||
}
|
||||
}
|
||||
],
|
||||
"standardOptions": {}
|
||||
},
|
||||
"matcher": {
|
||||
"value": "A"
|
||||
}
|
||||
},
|
||||
{
|
||||
"type": "special",
|
||||
"matcher": {
|
||||
"value": "D"
|
||||
},
|
||||
"properties": {
|
||||
"standardOptions": {
|
||||
"util": "humantimeSeconds"
|
||||
}
|
||||
}
|
||||
}
|
||||
],
|
||||
"version": "2.0.0",
|
||||
"type": "table",
|
||||
"layout": {
|
||||
"h": 15,
|
||||
"w": 24,
|
||||
"x": 0,
|
||||
"y": 1,
|
||||
"i": "3674dbfa-243a-49f6-baa5-b7f887c1afb0"
|
||||
},
|
||||
"id": "3674dbfa-243a-49f6-baa5-b7f887c1afb0"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user